之前我们曾分享过如何使用纯C#运行开源本地大模型Mixtral-8x7B。当时我们使用了llamasharp库和Mixtral模型在本地部署和推理。最近,我们注意到llamasharp已经更新到了0.11.1版本,可以支持今年2月份开源的llava-v1.6多模态大模型。出于尝试的想法,我们进行了集成,尽管在过程中遇到了一些困难,但幸运的是模型最终成功运行起来了。
先让我们来展示一下模型的图形理解结果吧:
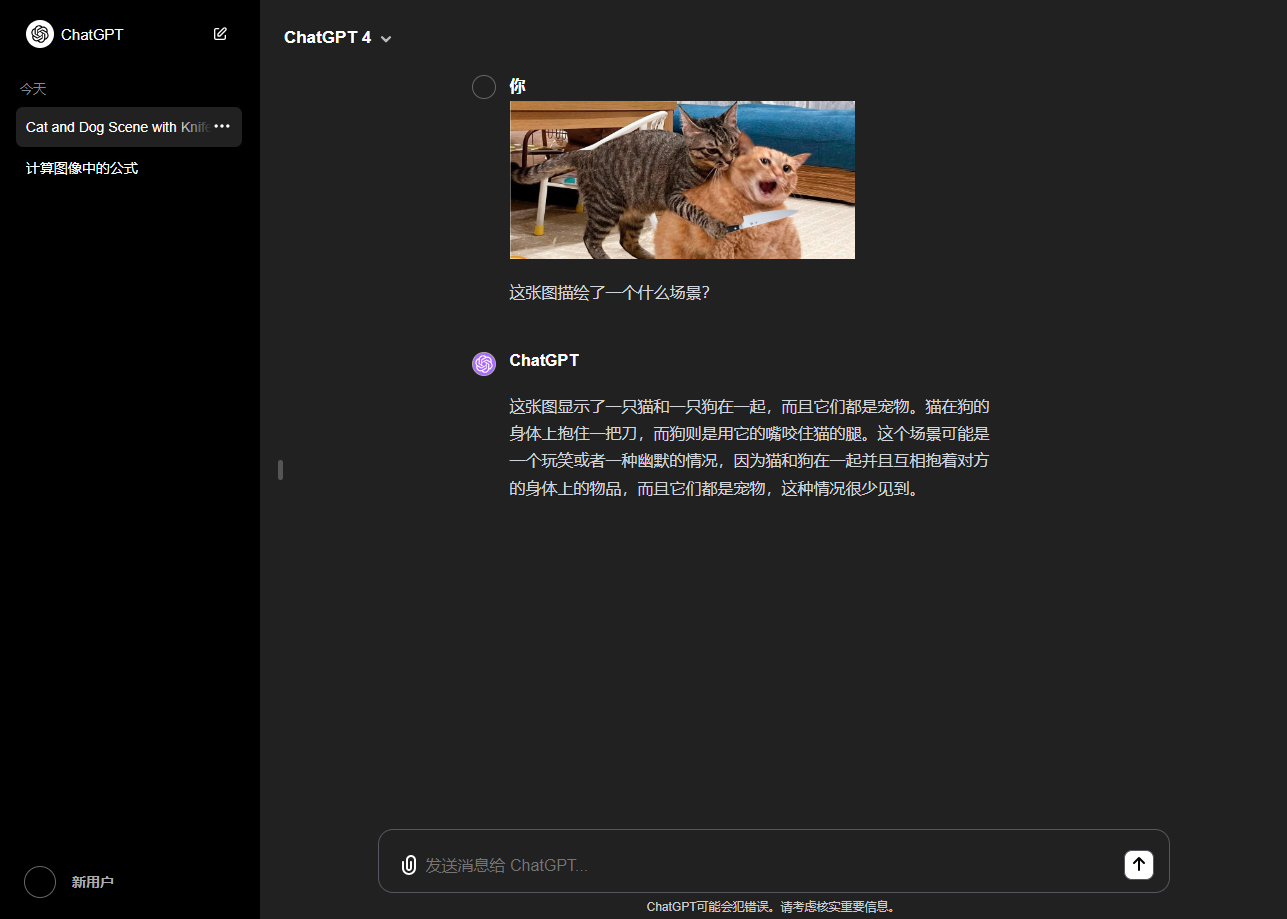
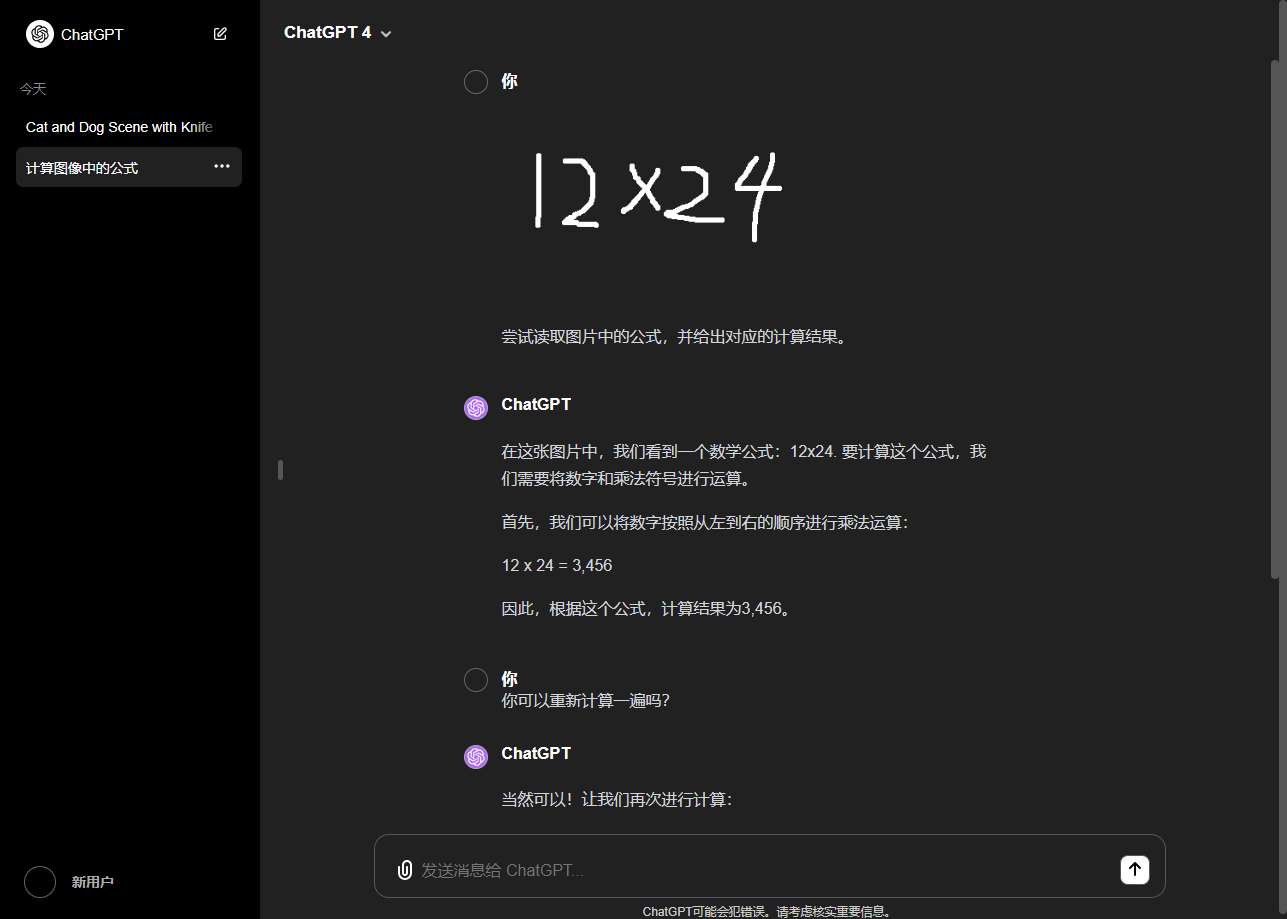
可以看到模型对图像还是有一些基本的理解能力,但是受限于模型的尺寸(7B),智能确实有限。而且基于目前的CPU推理确实速度感人。有感兴趣的小伙伴可以使用CUDA版本进行测试。
修改办法是双击csproj,修改<PackageReference Include="LLamaSharp.Backend.Cpu" Version="0.11.2" />为LLamaSharp.Backend.Cuda12 or LLamaSharp.Backend.Cuda11 (根据你的N卡环境的CUDA确定安装哪一个版本即可)。
接下来,我们来大概看看多模态部分的源代码实现,其实也比较简单:
多模态模型的实现原理是使用clip模型对图像到文本的映射生成对应的embedding。这一步和词嵌入类似,只不过这里是clip模型将图像转化成了另外一种形式的嵌入,然后输入多模态模型来进行图像推理。
所以多模态模型我们需要下载两个模型,一个用于图像CLIP嵌入,一个同于多模态推理:
//多模态模型:llava-v1.6-mistral-7b.Q4_K_M.gguf 下载地址:https://huggingface.co/mradermacher/llava-v1.6-mistral-7b-GGUF/resolve/main/llava-v1.6-mistral-7b.Q4_K_M.gguf
//CLIP模型:mmproj-mistral7b-f16-q6_k.gguf 下载地址:https://huggingface.co/cmp-nct/llava-1.6-gguf/resolve/main/mmproj-mistral7b-f16-q6_k.gguf?download=true
接着我们通过创建llamasharp上下文,就可以愉快的进行推理任务了,核心代码如下:
这里modelPath是你的多模态模型的本地加载地址,mmpmodelPath是CLIP模型的地址,都是相对路径。主要的坑过就是一开始我以为不需要加载CLIP模型,所以下载了llava就测试,结果模型要吗说没有找到图片要吗就乱说一通。
后来去llamasharp翻了一下案例才发现少了一个模型,第二个坑就是InferAsync这里输入内容时,如果要进行图像推理,必须要前置一个<image>的标签,否则模型会直接忽略你的图像,进行单纯的文本推理回答。
今天分享的内容都比较简单,项目也都更新到了git上,欢迎有兴趣的小伙伴下载+star:https://github.com/sd797994/LocalChatForLlama
标签:游戏攻略







