Stable diffusion中的models
Stable diffusion model也可以叫做checkpoint model,是预先训练好的Stable diffusion权重,用于生成特定风格的图像。模型生成的图像类型取决于训练图像。
如果训练数据中从未出现过猫的图像,模型就无法生成猫的图像。同样,如果只用猫的图像来训练模型,它也只会生成猫的图像。
这里我们将介绍什么是模型,一些流行的模型,以及如何安装、使用和合并它们。
微调模型Fine-tuned models
在计算机视觉和自然语言处理领域,微调模型是指使用预训练模型,并在特定任务上进行进一步的训练,以使其适应特定的数据集或问题。通过微调,模型可以更好地理解和处理特定领域的信息,从而提高其性能和准确性。
微调的步骤
- 选择预训练模型 :首先选择一个在大规模数据集上进行了预训练的模型,如BERT、ResNet等。
- 冻结部分层 :通常情况下,我们会冻结模型的一部分层,以保留其在预训练数据集上学到的特征。
- 添加新层 :根据特定任务的需求,我们会向模型中添加新的层或调整现有层的结构。
- 微调模型 :利用特定任务的数据集,对模型进行进一步训练,以使其在该任务上表现更好。
微调的应用
微调模型在各种领域都有广泛的应用,包括情感分析、图像分类、语义分割等。通过微调,模型可以适应不同领域的特定数据分布,从而提高其泛化能力和适应性。
微调模型是一种有效的方法,可以帮助我们利用预训练模型的知识,快速构建并优化适用于特定任务的模型。通过合理的微调策略,我们可以更好地利用现有的模型和数据,从而取得更好的效果。
为什么人们要微调Stable diffusion模型?
Stable diffusion base模型非常出色,但并不是万能的。例如,它可以生成带有“动漫”关键词的动漫风格图片。然而,它可能很难生成特定子类型的动漫图片。
所以,通过微调可以生成不同风格的stable diffusion模型。下面是我们使用相同的提示词和设置,但是用不同模型生成的图片。
提示词如下:
a girl,0lg4kury,
其中0lg4kury是一个embedding。
我们分别使用了AnythingV5,dreamshaper_8和majicmixRealistic_v7这三个checkpoint来生成最终的图片。
大家可以看到,同样的提示词最后的图片效果是不同的。
其中AnythingV5是卡通风格,dreamshaper是真实绘画风格,而majicmixRealistic是真实照片风格。

使用模型是实现特定风格的简单方式。
模型是如何创建的?
checkpoint模型是一种通过额外训练和Dreambooth技术创建的模型,它们基于稳定扩散v1.5或XL等基础模型进行改进。这些方法允许用户根据自己的特定需求和兴趣来定制AI模型,从而生成更加个性化和专业化的图像内容。
额外训练 : 额外训练是指使用特定的数据集对基础模型进行进一步的训练。这种方法可以让你专注于某个特定的主题或领域,例如cat。通过使用相关的数据集,你可以调整模型的输出,使其更倾向于生成具有cat特征的图像。这种方法的关键在于选择合适的数据集,并确保其与你的生成目标相匹配。
Dreambooth : Dreambooth是由谷歌开发的一种技术,它允许用户通过少量的自定义图片(通常是3-5张)将特定的主题或对象注入到文本到图像模型中。例如,如果你想要在生成的图像中包含自己的形象,你可以拍摄几张照片,并通过Dreambooth将这些图片与模型结合。这样,当你在生成图像时使用特定的关键词,模型就会根据这些图片生成包含你形象的图像。Dreambooth训练的模型依赖于这个关键词来触发特定的生成效果。
除了checkpoint模型,还有其他的模型类型,如embedding、LoRA、LyCORIS和超网络,它们各自有不同的特点和应用场景。文本反演通过定义新的关键字来描述特定的对象或风格,而LoRA和LyCORIS则提供了更快速和灵活的训练选项。超网络则是一种在原有模型基础上添加附加网络的方法,用于学习新的生成特征。
在本文中,我们将重点关注checkpoint模型。
热门的stable diffussion模型
你可以在C站上找到成千上万的模型,这里我来列举几个比较常用的模型,供大家参考:
Stable diffusion v1.4
这是Stability AI于2022年8月发布的v1.4版本, 是首个公开可用的稳定扩散模型。
这是一个通用模型,能够产生各种风格的作品,但是现在已经很少有人使用了,现在大多数人已经转向了v1.5模型。
Stable diffusion v1.5
stable diffusion v1.5 是由 Stability AI 的合作伙伴 Runway ML 于 2022 年 10 月发布。该模型基于 v1.2 并进行了进一步的训练。
模型页面未提及改进之处。与 v1.4 相比,它产生了稍微不同的结果,但尚不清楚它们是否更好。
与 v1.4 一样,您可以将 v1.5 视为通用模型。根据我的经验,v1.5 是作为初始模型的不错选择,并且可以与 v1.4 互换使用。
Realistic Vision
Realistic Vision 非常适合生成任何逼真的内容,无论是人物、物体还是场景。
DreamShaper
DreamShaper模型经过微调,适用于介于照片逼真和计算机图形之间的肖像插画风格。
majicMIX realistic
majicMIX是一个很棒的写实模型。
SDXL模型
SDXL模型是备受赞誉的v1.5和被遗忘的v2模型的升级版本。
使用SDXL模型的好处包括:
-
更高的原生分辨率- 1024像素,而v1.5只有512像素
-
更高的图像质量(与v1.5基础模型相比)
-
能够生成可读的文本
-
更容易生成较暗的图像
Anything
Anything 是一个专门训练的模型,用于生成高质量的动漫风格图片。它对于将名人形象转换为动漫风格非常有用,然后可以与插画元素无缝融合。
当然还有其他的一些非常不错的模型,大家可以多逛逛C站,那里有你所要的一切。
其他不错的模型
Deliberate v2

Deliberate v2 是可以呈现逼真的插图。其结果可能会出乎意料地好。每当你有一个好的提示时,切换到这个模型,你会得到惊喜的结果。
F222

F222模型在生成具有正确身体部位关系的美丽女性肖像方面非常棒。
ChilloutMix

ChilloutMix是一个专门用于生成亚洲女性照片模型。它就像是F222的亚洲版。
在Stable Diffusion webUI中安装和使用models
要在web GUI中安装模型,可以从C站或者其他的网站上下载对应的模型,并将checkpoint模型文件放在以下文件夹中:
stable-diffusion-webui/models/Stable-diffusion/
然后点击左侧顶部checkpoint下拉框旁边的刷新按钮。
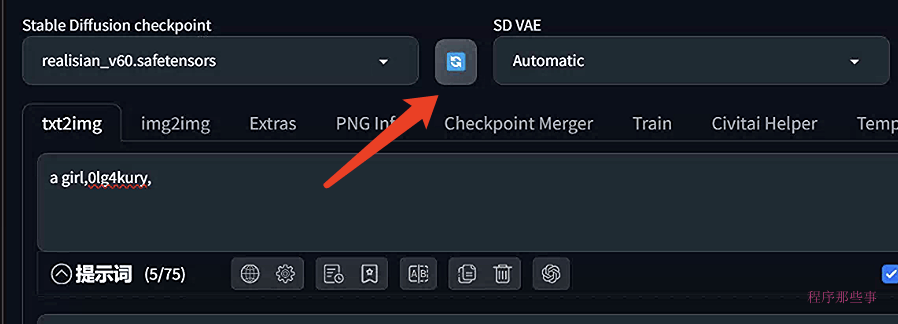
在这个下拉列表中,你可以看到刚刚下载并安装好的模型。
还有一种方法,就是在txt2img或img2img页面中,选择 Checkpoints 标签页,也可以看到对应的模型。
CLIP Skip
什么是CLIP Skip?
CLIP Skip是Stable Diffusion中用于图像生成的CLIP文本嵌入网络的一项功能,它表示跳过最后的几层。
CLIP是Stable Diffusion v1.5模型中使用的语言模型,它将提示中的文本标记转换为embedding。它是一个包含许多层的深度神经网络模型。CLIP Skip指的是要跳过多少个最后的层。在AUTOMATIC1111和许多Stable Diffusion软件中,CLIP Skip为1时不跳过任何层。CLIP Skip为2时跳过最后一层,依此类推。
为什么要跳过一些CLIP层?因为神经网络在通过层时会总结信息。层越早,包含的信息就越丰富。
跳过CLIP层对图像可能会产生显著影响。许多动漫模型都是用CLIP Skip为2进行训练的。
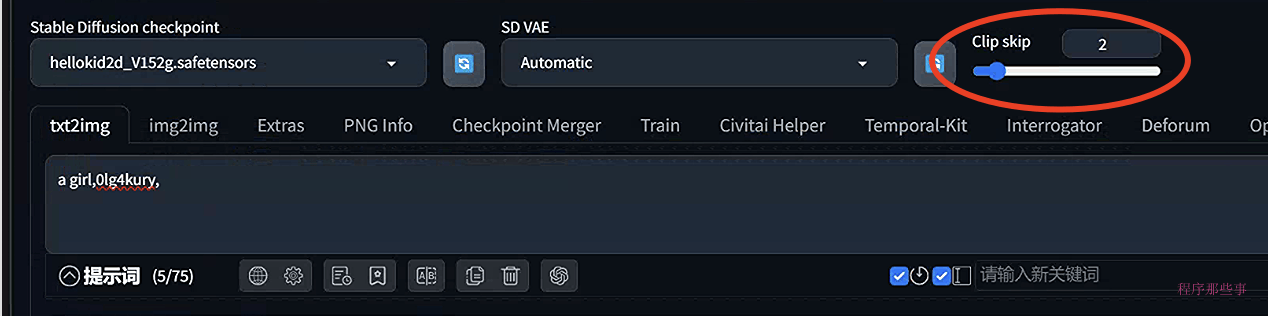
在C站上,有些模型会专门标出对应的clip skip是多少,比如这个hellokid2d模型,他的clip skip就是2:
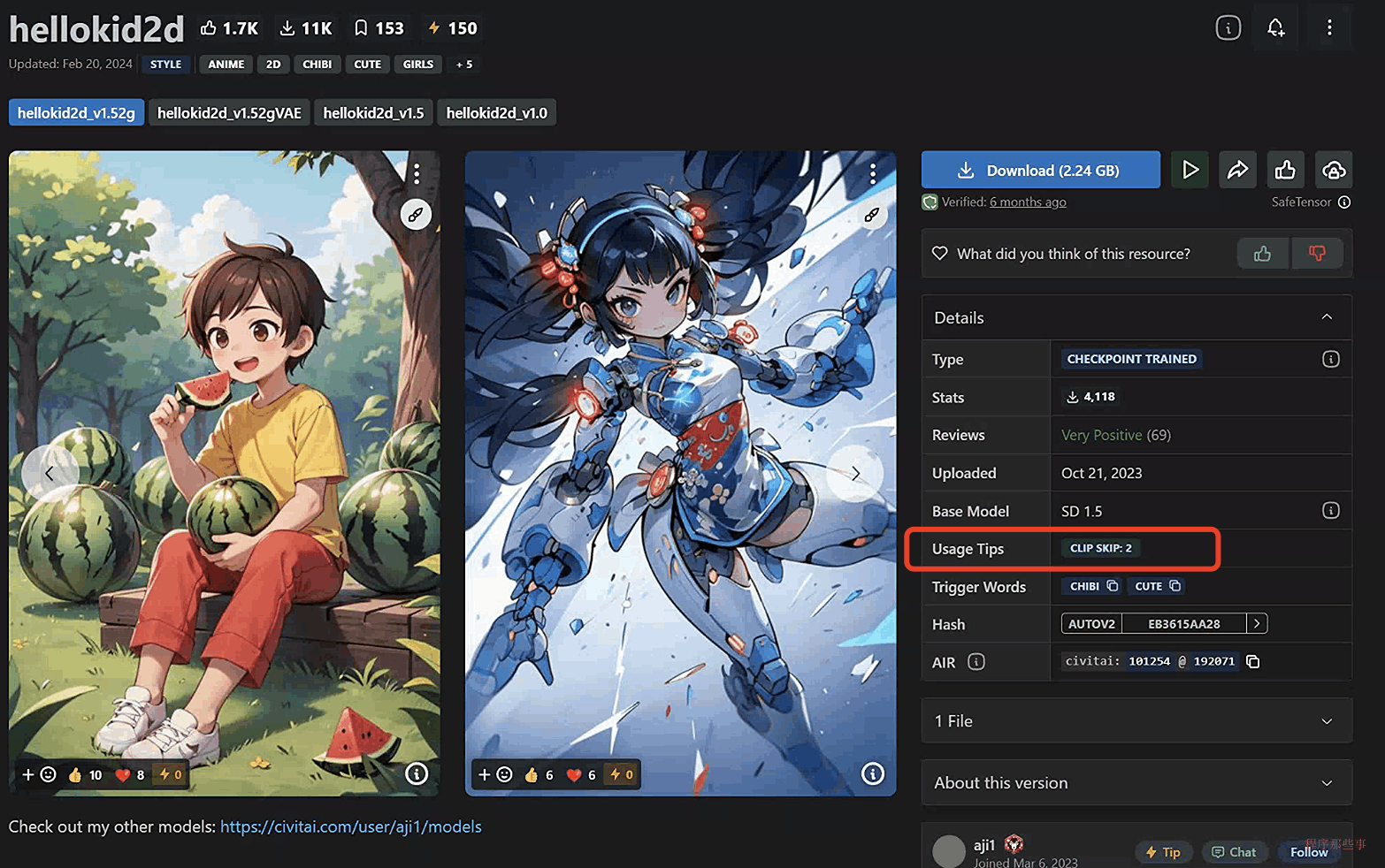
我们用这个模型为例,来尝试一下不同clip skip的效果:

在web UI中设置clip Skip
正常情况下在文生图或者图生图界面上是看不到clip Skip选项的。 你需要去到 Settings > User Interface > User Interface页面, 在Quicksettings list中添加 CLIP_stop_at_last_layer . 然后点击 Apply Settings 最后 Reload UI .
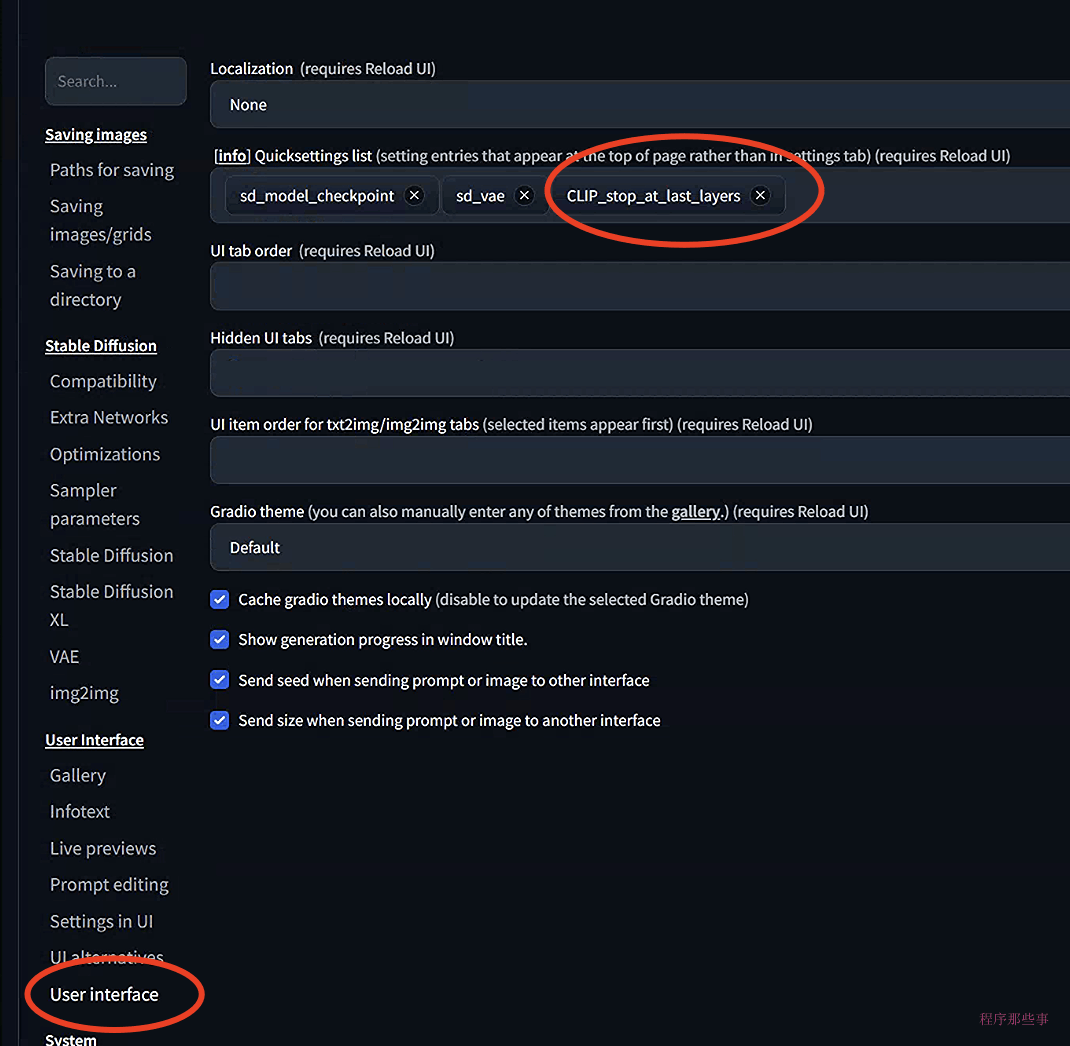
clip skip 滑动按钮就会显示在webUI界面上了。
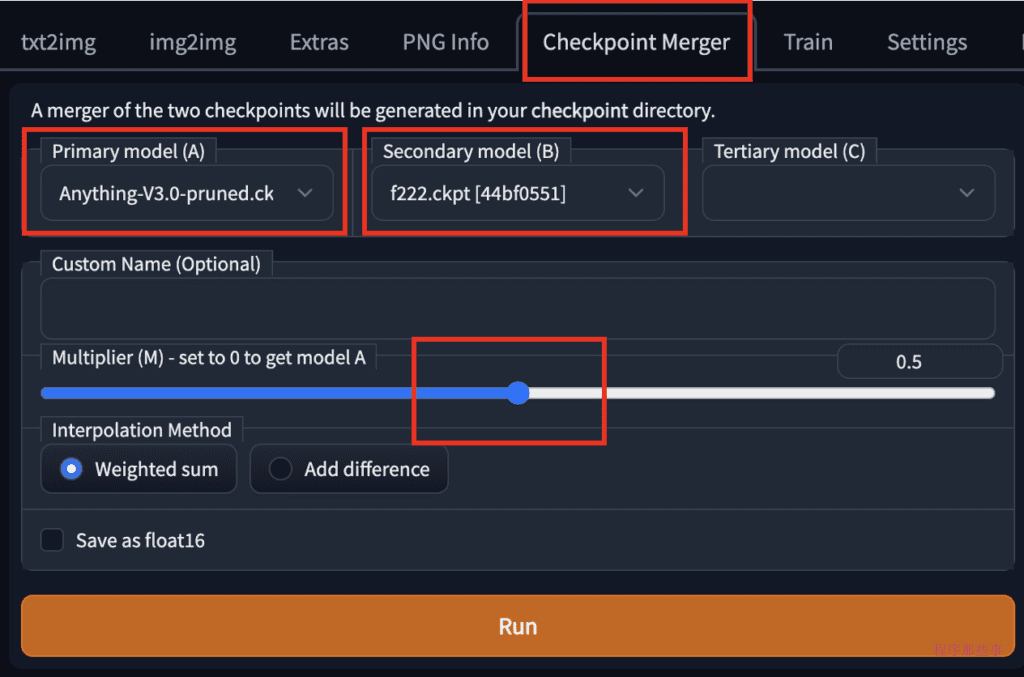
合并两个models
在webUI中合并两个models是非常简单的事情,我们导航到checkpoint Merger页面,选择好对应的两个模型,并调整乘数(M)以调整两个模型的相对权重。将其设置为0.5将以相等的权重合并两个模型。
按下 Run 后,就会把两个模型合并成一个新的模型。
你可以根据自己的爱好来尝试合并不同的模型,通过调整对应的权重,你可以得到意想不到的结果。
Stable Diffusions model的文件格式
在模型下载页面上,您可能会看到几种模型文件格式。
- 剪枝 (Pruned)
- 完整 (Full)
- 仅EMA (EMA-only)
- FP16
- FP32
- .pt
- .safetensor
这很令人困惑!您应该下载哪一个?
Pruned vs Full vs EMA-only
一些 Stable Diffusion checkpoint模型由两组权重组成:最后训练步骤后的权重和过去几个训练步骤的平均权重,称为 EMA(指数移动平均)。
如果您只对使用 模型 感兴趣,可以下载 EMA-only。这些是您在使用模型时使用的权重。它们有时被称为 Pruned模型 。
如果您想要用额外的训练对模型进行微调,那么只需要 Full模型 (即由两组权重组成的检查点文件)。
因此,如果您想要用它来生成图像,请下载 Pruned 或 EMA-only 。这可以节省一些磁盘空间,哦,不对,是非常多非常多的空间。
Fp16 和 fp32 模型
FP 代表浮点。它是计算机存储十进制数的方式。这里的十进制数是模型权重。FP16 每个数字占用 16 位,称为半精度。FP32 占用 32 位,称为全精度。
深度学习模型(如 Stable Diffusion)的训练数据非常嘈杂。您很少需要全精度模型。额外的精度只是存储噪音!
因此,如果有可用的话,请下载 FP16 模型。它们大约是大小的一半。这可以节省几个 GB 的空间!
Safetensor 模型
原始的 pytorch 模型格式是
.pt
。这种格式的缺点是不安全。如果有人在其中打包恶意代码。当您使用模型时,恶意代码就可以在您的计算机上运行。
Safetensors 是 PT 模型格式的改进版本。它执行与存储权重相同的功能,但不会执行任何代码。因此,如果可能的话,请下载 safetensors 版本。如果没有这个版本,那么请从可信赖的来源下载 PT 文件。
其他模型类型
在stable diffusion中,有四种主要类型的文件可以称为“模型”。
Checkpoint 模型 是真正的 Stable Diffusion 模型。它们包含生成图像所需的所有内容。不需要额外的文件。它们很大,通常为 2 - 7 GB。
文本反转(也称为embedding)是定义生成新对象或样式的新关键词的小文件。它们很小,通常为 10 - 100 KB。必须与 Checkpoint 模型一起使用。
LoRA 模型 是用于修改样式的 Checkpoint 模型的小补丁文件。它们通常为 10-200 MB。必须与 Checkpoint 模型一起使用。
超网络 是添加到 Checkpoint 模型的附加网络模块。它们通常为 5 - 300 MB。必须与 Checkpoint 模型一起使用。
总结
在这篇文章,我介绍了 Stable Diffusion 模型,它们是如何制作的,一些常见的模型以及如何合并它们。欢迎大家自行尝试。
点我查看更多精彩内容:www.flydean.com
标签:游戏攻略







