Hugging Face的Transformers是一个功能强大的机器学习框架,提供了一系列API和工具,用于预训练模型的下载和训练。为了避免重复下载,提高训练效率,Transformers会自动下载和缓存模型的权重、词表等资源,默认存储在
~/.cache/huggingface/hub
目录下。这个缓存数据的机制。
但是,当有多用户或多节点处理相同或关联任务时,每个设备都需要重复下载相同的模型和数据集,这势必造成管理难度增大和浪费网络资源的问题。
要解决这个问题,可以将Hugging Face的缓存数据目录设置在共享存储上,让每个需要该资源的用户能够共享使用同一份数据。
在共享存储的选择上,如果设备不多且都在本地,则可以考虑使用Samba或NFS共享。如果计算资源分布在不同的云或不同地区的机房,则需要采用性能和一致性都更有保证的分布式文件系统,JuiceFS就是一个非常适合的方案。
利用JuiceFS分布式、多端共享、强一致性等特性,不同计算节点间可以高效共享和迁移训练资源,免于重复准备相同数据,从而显著优化资源使用和存储管理,提高整个AI模型的训练效率。
JuiceFS架构
JuiceFS是开源的云原生分布式文件系统,采用了数据与元数据分离存储的技术架构,以对象存储作为底层存储来保存数据,以键值存储或关系型数据库作为元数据引擎来保存文件的元数据。这些计算资源可以自行搭建,也可以在云平台上购买,因此JuiceFS是很容易搭建和使用的。
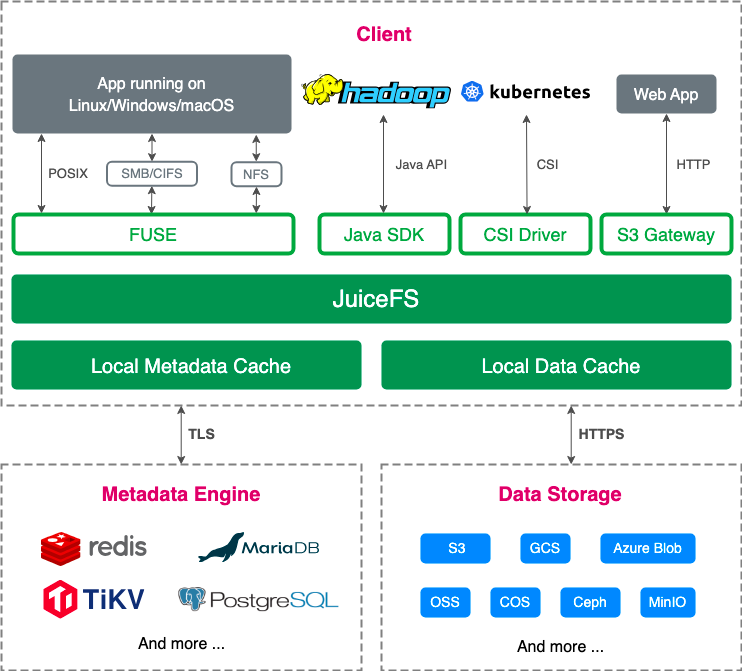
底层数据存储
在底层存储方面,JuiceFS支持市面上几乎所有主流的公有云对象存储服务,比如Amazon S3、Google Cloud Storage、阿里云OSS等,也支持MinIO、Ceph等私有部署的对象存储。
元数据引擎
在元数据引擎方面,JuiceFS支持Redis、MySQL、PostgreSQL等多种数据库,另外,也可选购JuiceFS官方的云服务版本,它采用Juicedata官方自研的高性能分布式元数据引擎,可以满足更高性能要求的场景需求。
JuiceFS客户端
JuiceFS分为开源版和云服务版,它们所使用的客户端不同,但使用方法基本一致。本文以开源版为例进行介绍。
JuiceFS社区版提供了跨平台的客户端,支持Linux、macOS、Windows等操作系统,可以在各种环境中使用。
当你基于这些计算资源搭建了一个JuiceFS文件系统以后,就可以通过JuiceFS客户端提供的API或者FUSE接口来访问JuiceFS文件系统,实现文件的读写、元数据的查询等操作。
对于Hugging Face的缓存数据存储,可以将JuiceFS挂载到
~/.cache/huggingface/
目录下,这样Hugging Face相关的数据就可以存储到JuiceFS中。另外,也可以通过设置环境变量自定义Hugging Face缓存目录位置,指向JuiceFS挂载的目录。
接下来就展开介绍如何创建JuiceFS文件系统,以及将JuiceFS用于Hugging Face的缓存目录的两种方法。
标签:游戏攻略







