时隔很久,终于忙里偷闲可以搞一搞rCore,上帝啊,保佑我日更吧,我真的很想学会.
导读部分
首先还是要看 官方文档 .
我决定看一遍然后自己表述一遍(智将).
这里反复提到MMU,就是因为之前学MCU的时候有一个疑问,就是为什么MCU上不选择跑一个Linux,当时找到的答案是因为没有MMU.
MMU的全称是Memory Management Unit,中文译为内存管理单元.那时候不知道为什么硬件上需要这样一个内存管理单元,现在我们就可以一探究竟.
反复提到他是提醒我们 虚拟地址和物理地址的转换 不是由我们编写的OS实现的,而是OS写了一个接口,通过这个接口 调用 了MMU实现的.
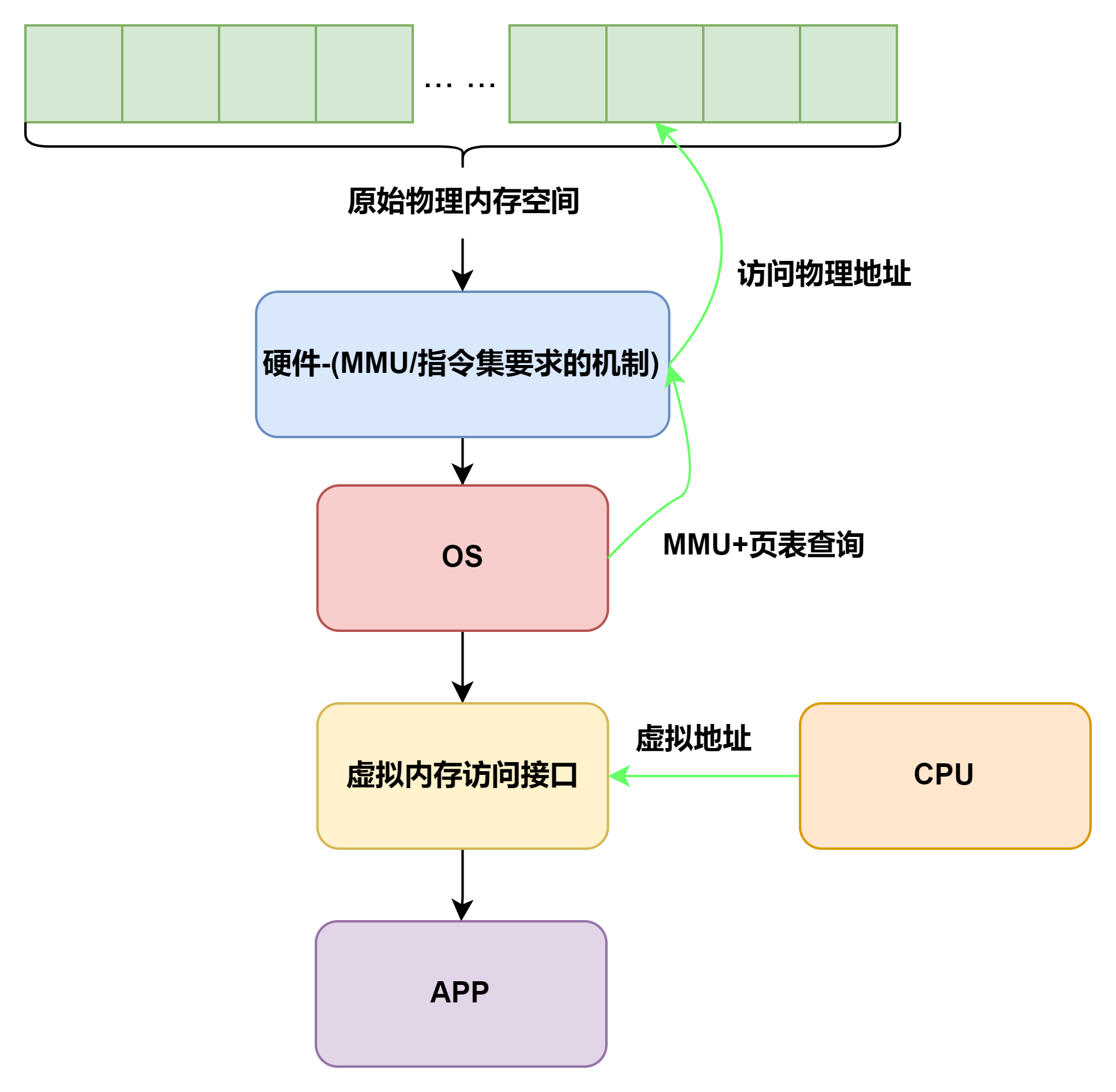
那么最重要的就是 地址空间 这个概念,有了地址空间就可以在 内核 中构建虚实地址空间的 映射 机制.
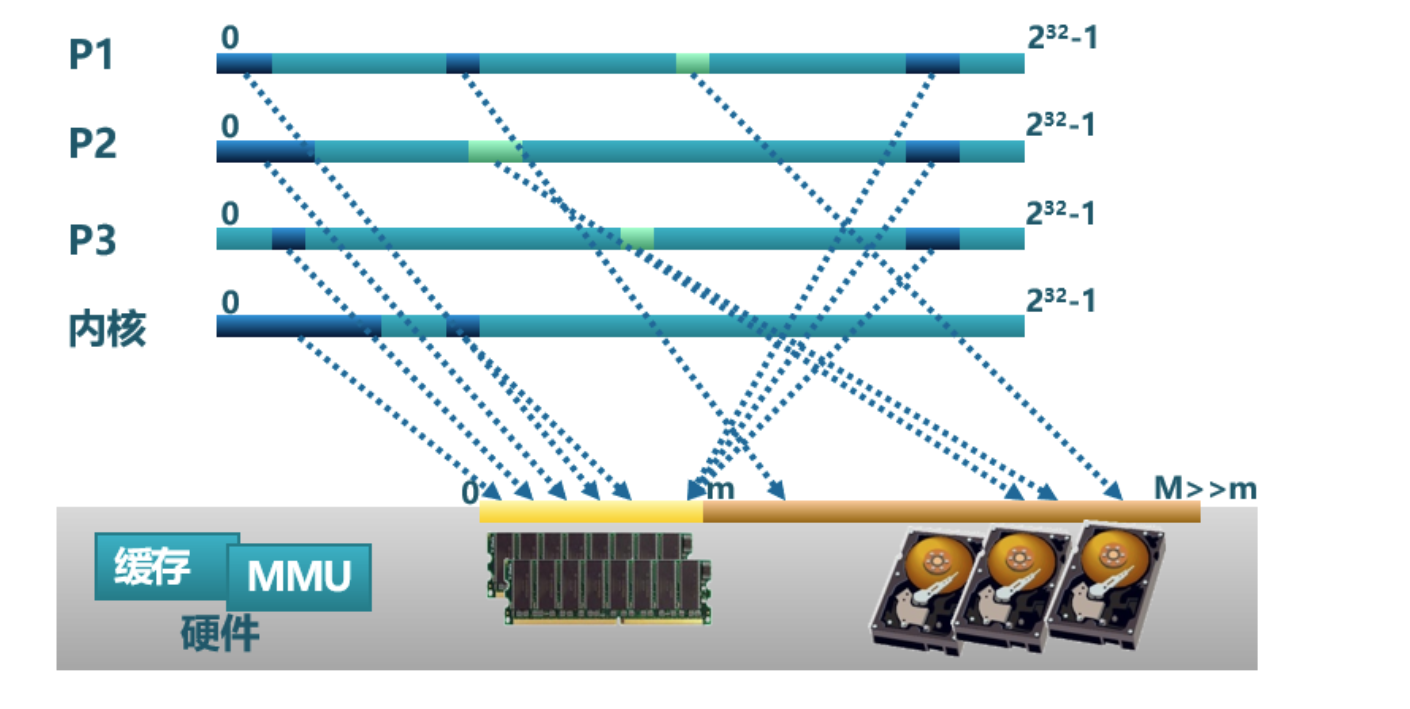
这里谈谈我对上边这张图的理解:
P1~P3是每个应用自己的地址空间,内核则是操作系统内核的地址空间.对于每段地址空间,地址都是从
0开始的到2^32-1.而我们利用硬件机制(例如MMU+页表查询)完成这些地址空间对物理地址的映射.
地址虚拟化出现之前
这部分的内容是非常有意义的.尤其是提到了:
后来,为了降低等待 I/O 带来的无意义的 CPU 资源损耗,多道程序出现了。而为了提升用户的交互式体验,提高生产力,分时多任务系统诞生了。它们的特点在于:应用开始多出了一种“暂停”状态,这可能来源于它主动 yield 交出 CPU 资源,或是在执行了足够长时间之后被内核强制性放弃处理器。
这部分不就是我们上一部分学到的 分时多道程序 吗?
那么那时候我们是怎么做的呢?
实际上我们是为所有的APP都 单独 开了一个栈,这样就有比较高的内存损耗.
这时候就可以读懂这段文字里边:
经有一种省内存的做法是每个应用仍然和在批处理系统中一样独占内核之外的整块内存,当暂停的时候,内核负责将它的代码、数据保存在外存(如硬盘)中,然后把即将换入的应用在外存上的代码、数据恢复到内存,这些都做完之后才能开始执行新的应用。
那么这种方法就是对每个APP单独占据一段内存的 解决方法之一 ,即使用外存保存.
那么众所周知,硬盘的读取速度肯定是不如内存的,那么就很巧妙地引入本节的新内容了.
最后文档总结了一下上一章的弊端:
- 从应用开发的角度看,需要应用程序决定自己会被加载到哪个物理地址运行,需要直接访问真实的物理内存。这就要求应用开发者对于硬件的特性和使用方法有更多了解,产生额外的学习成本,也会为应用的开发和调试带来不便。
- 从内核的角度来看,将直接访问物理内存的权力下放到应用会使得它难以对应用程序的访存行为进行有效管理,已有的特权级机制亦无法阻止很多来自应用程序的恶意行为。
加一层抽象加强内存管理
Any problem in computer science can be solved with another layer of indirection.
这句话出自麻省理工学院的计算机科学系教授 巴特勒·兰普森(Butler Lampson) .
这里对我上边的半猜测半理解进行了补充,尤其是这个 不一定真实存在 非常重要.
最终,到目前为止仍被操作系统内核广泛使用的抽象被称为 地址空间 (Address Space) 。某种程度上讲,可以将它看成一块巨大但 并不一定真实存在 的内存。
在每个应用程序的视角里,操作系统分配给应用程序一个地址范围受限( 容量很大 ), 独占 的连续地址空间(其中有些地方被操作系统 限制 不能访问,如内核本身占用的虚地址空间等),因此应用程序可以在划分给它的地址空间中随意规划内存布局,它的各个段也就可以分别放置在地址空间中它希望的位置(当然是操作系统允许应用访问的地址)。
这种地址被称为 虚拟地址 (Virtual Address) 。
#TODO
学习
MMU
和
TLB
的硬件机制.
事实上,特权级机制被拓展,使得应用不再具有直接访问物理内存的能力。
这个还和特权级机制有关了,这里也去查一下 RISC-V参考书 ,翻到10.6:
- S 模式提供了一种传统的虚拟内存系统,它将内存划分为固定大小的页来进行地址转 换和对内存内容的保护。
- 启用分页的时候,大多数地址(包括 load 和 store 的有效地址和 PC 中的地址) 都是虚拟地址 。
- 要 访问物理内存 ,它们必须被转换为真正的物理地址,这通过遍历一种称为 页表 的 高基数树 实现。
- 页表中的 叶节点 指示虚地址 是否已经被映射到了真正的物理页面
- 如果是,则指示了哪些权限模式和通过哪种类型的访问可以操作这个页。
- 访问未被映射的页或访问权限不足会导致页错误例外(page fault exception)。
地址空间抽象的好处
- 由于每个应用独占一个地址空间,里面只含有自己的各个段,于是它可以随意规划属于它自己的各个段的分布而无需考虑和其他应用冲突;
- 同时鉴于应用只能通过虚拟地址读写它自己的地址空间,它完全无法窃取或者破坏其他应用的数据,毕竟那些段在其他应用的地址空间内,这是它没有能力去访问的。
这是地址空间抽象和具体硬件机制对应用程序执行的安全性和稳定性的一种保障。
增加硬件加速虚实地址转换
这一部分讲的内容非常好,要去看看内容和那张图: 地址空间 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
这张图就非常合理,
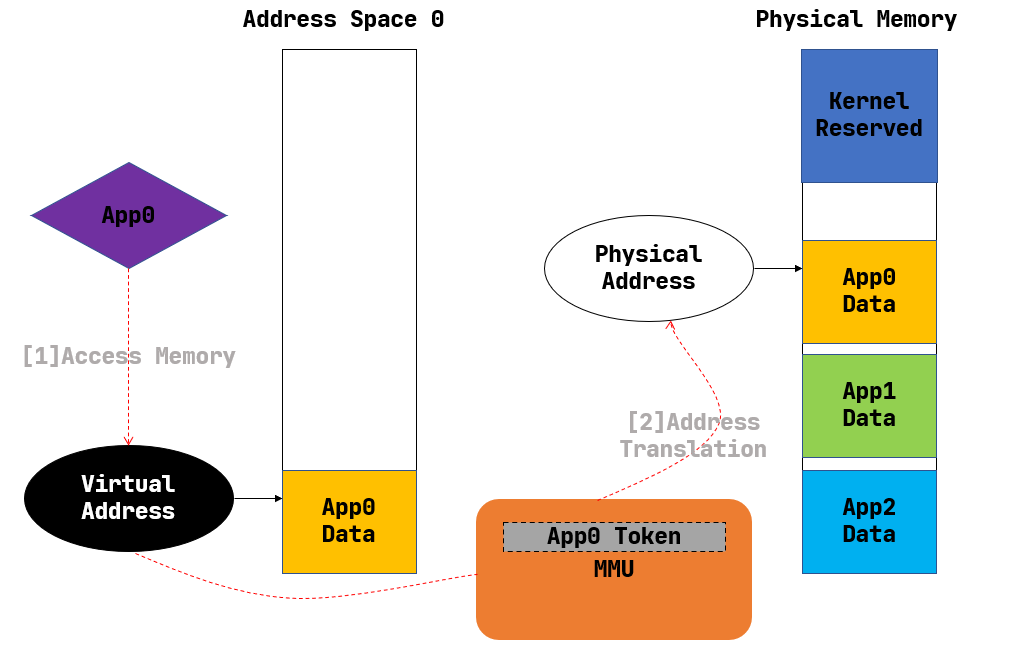
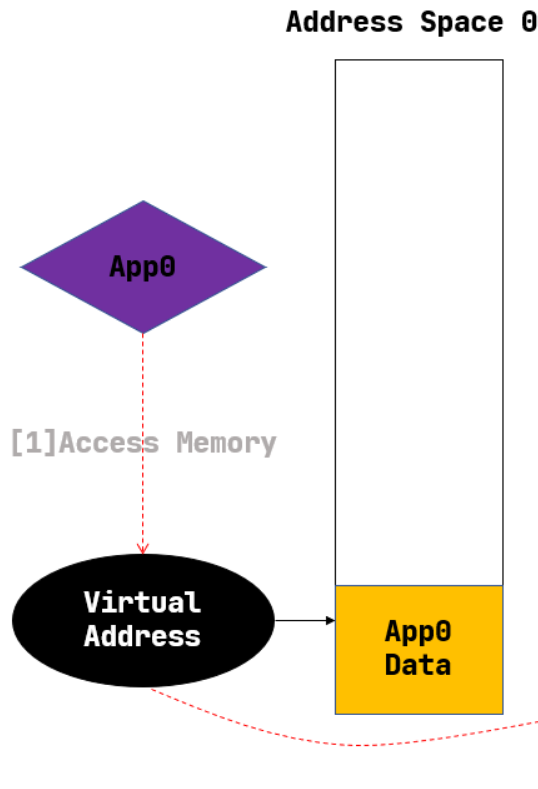
只看左半边,在APP的视角,
App0
通过访问一个
虚拟地址
Virtual Address
,访问到了它的地址空间
Address Space 0
,并且对应找到了数据
App0 Data
:
再看右半边,实际上这个访问操作由
OS
和硬件代理了,通过
MMU
转化
Virtual Address
为物理地址
Physical Address
,再通过这个物理地址访问到储存在
物理内存
Physical Memory
中的
App0 Data
:
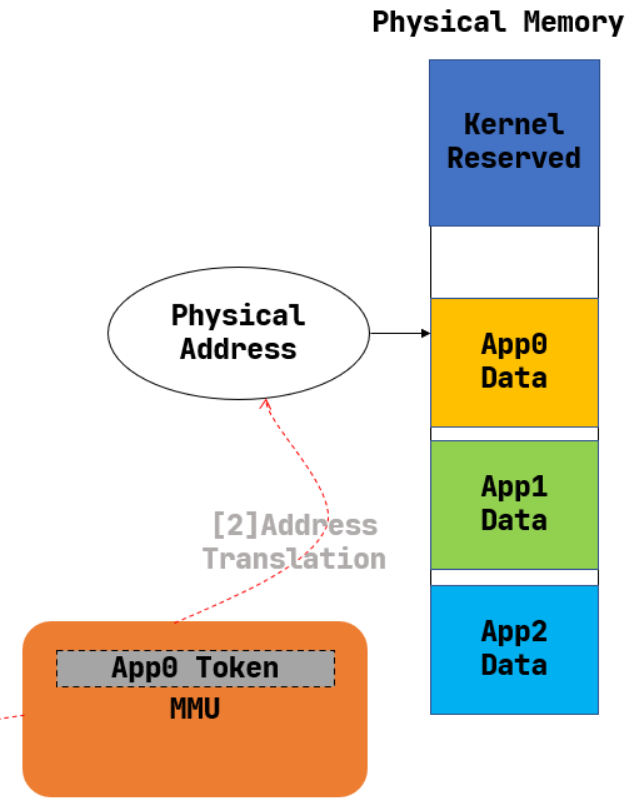
这里注意一下这张图中的
Physical Memory
部分,这里有一些有趣的点,趁着这些点来学会一些东西.
-
Kernel Reserved部分是操作系统的内核占用的内存 -
这边不仅储存了
App 0 Data同时还储存了App 1 Data和App 2 Data.实际上说明了,在App的视角,它通过虚拟内存能够看到的只有自己的Data,而物理内存中也存着其它的Data.
那么回到这一节的标题
增加硬件加速
,手册中是这么描述的:
操作系统可以设计巧妙的数据结构来表示地址空间。但如果完全由操作系统来完成转换每次处理器地址访问所需的虚实地址转换,那 开销就太大 了。这就需要扩展硬件功能来加速地址转换过程(回忆 计算机组成原理 课上讲的
MMU和TLB)。
这说明虚拟地址的实现依赖于:
- 操作系统设计 巧妙的数据结构
-
MMU和TLB的硬件加速
这段话增强了我们对操作系统设计理念的理解,对 硬件资源抽象化 :
回过头来,在介绍内核对于 CPU 资源的抽象——时分复用的时候,我们曾经提到它为应用制造了一种每个应用独占整个 CPU 的幻象,而隐藏了多个应用分时共享 CPU 的实质。而地址空间也是如此,应用只需、也只能看到它独占整个地址空间的幻象,而藏在背后的实质仍然是多个应用共享物理内存,它们的数据分别存放在内存的不同位置。
分段内存管理
分段内存管理的方法曾经是一种流行的内存管理方法,通过学习它也可以学到很多关于内存管理的知识.
#TODO
常数大小内存+线性映射
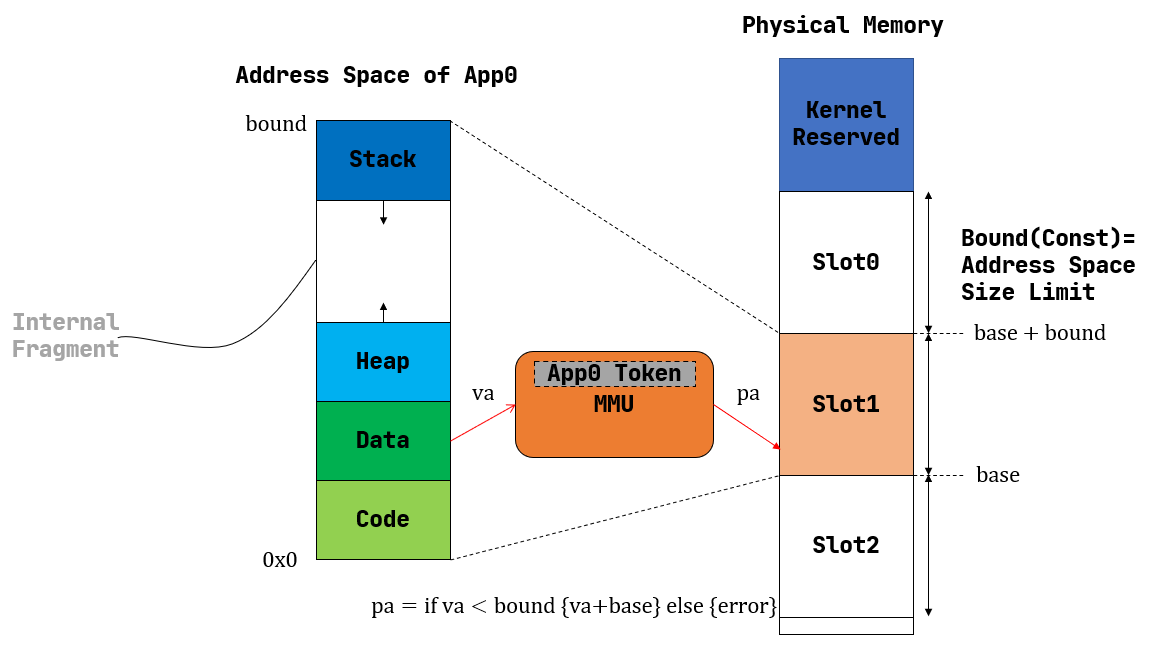
如图所示的是曾经的一种分段内存管理的方案.
可以看到这里非常暴力地将
每个APP的内存大小
(不是单个APP设置对应大小)都强制分配为
bound
.这时候我们往往想到之前在16和17节学到的,通过
build.rs
和
link_app.S
将编译好的
.bin
文件链接进内核的方式.
似乎给每个APP分配一个 插槽(Slot) 的方式并不怎么讨喜,因为我们直接编译进内核,似乎内存大小都是固定的.
这里我们不得不打破心中的幻觉:
- 16,17节学到的内容,只有
stack而没有可以动态分配内存的heap- 那个阶段的APP没有动态内存分配器
- 没有动态内存分配器时怎么实现动态数组等灵活的数据结构呢? 直接创建一个非常大的数组 .
- 16,17节学到的内容中,包括22节学到的多道程序的内容,在编译的时候需要设置好初始的内存,而没有自己的 内存空间 ,
- 这决定的编译好的
.bin文件只能被加载到固定的位置- 这使APP既 不安全 (可以访问到物理内存)又不 灵活 (无法使用动态内存).
那么继续看图说话,我们可以看到
Address Space of App0
:
-
Code段和在 物理内存 中的表现 相同 ,直接被安置在了一个固定位置,只不过这个位置的地址已经不是物理地址,而是直接从虚拟地址0x0开始. -
而代表全局变量的
Data段. -
可以向下增长的
stack,但是注意一个APP的stack的最大大小是在编译完之后就知道的. -
可以向上增长的
heap.运行时才知道的变量要申请到heap里边.
这时候
MMU
只需要扮演一个
位图
的作用.
位图是一个二进制数组,其中的每个位(bit)代表内存中的一个特定区域(如一个内存页或内存块)。位图中的每个位可以是0或1,0通常表示对应的内存区域是空闲的,而1表示已被分配。
当程序需要分配内存时,操作系统会检查位图,找到足够数量的连续0(表示空闲区域),并将这些位设置为1,表示内存已被分配。
当程序释放内存时,操作系统会将位图中相应的位重新设置为0,表示这些内存区域再次变为空闲。
那么这个问题就非常简单了,其实我们这一部分的思路就分解为三步:
- 现在的内存分配方式是什么样的
- MMU在其中做了什么样的工作
- 内存碎片是怎么产生的
这时候内存碎片就很好说.
这里简单地把 已经分配的内存中没有被利用到的内存 叫做 内碎片 .
那么这是最典型的内碎片的问题,每次分配的内存都恒为
bound
,那么有多少APP能够刚好利用完呢,这样的利用率就很低了.
分段管理策略
那么为了解决上述的 内碎片 的问题,找到了一种分段管理的策略.
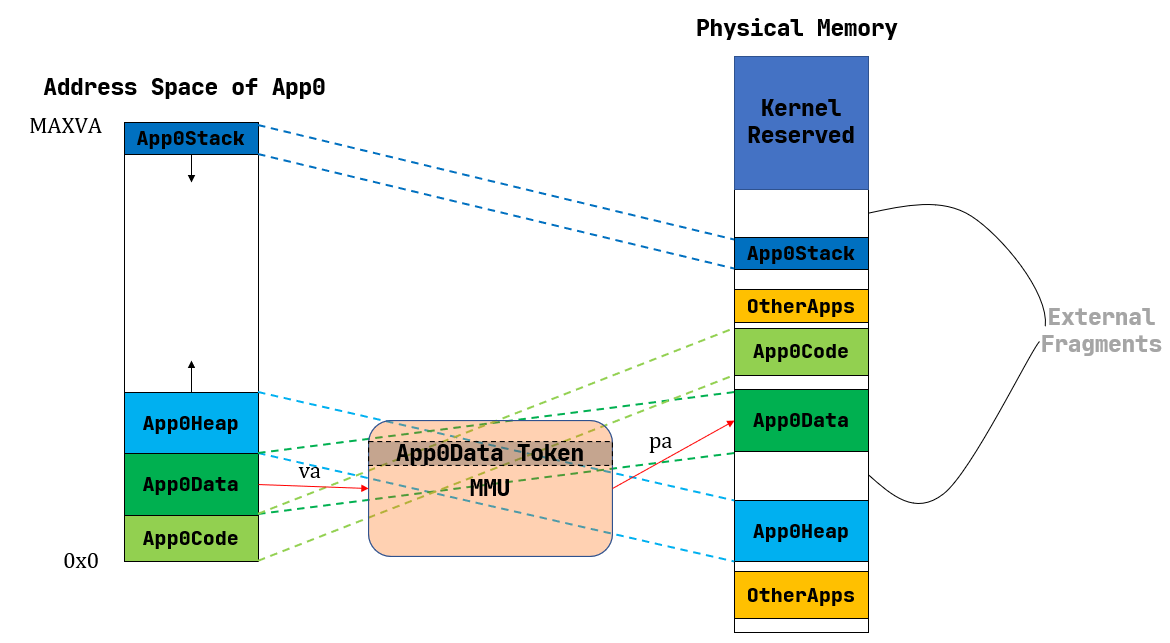
仍然是看图说话,解决我们上述讲的 三个问题 .
可以看到 MMU 分别对APP中的 段 进行一个线性映射,每一个部分是一个 段 .
注意, 实验指导书 忽略了一些细节:
简单起见,我们这里忽略一些不必要的细节。比如应用在以虚拟地址为索引访问地址空间的时候,它如何知道该地址属于哪个段,从而硬件可以使用正确的一对 base/bound 寄存器进行合法性检查和完成实际的地址转换。
这里其实就很容易再次想到关于 堆 的问题, 实验指导书 中提到的:
堆的情况可能比较特殊,它的大小可能会在运行时增长,但是那需要应用通过系统调用向内核请求。
这时候就没有 内碎片 的问题了.
思考之前学到
buddy-system
的内存分配问题,实际上每段之间的对齐是需要和
最小可访问内存大小
相关的,使用分段的方法做内存管理就会造成各种
不可利用(不能分配出去)
的内存碎片,一般叫
外碎片
.当然,对于外碎片还是可以使用各种方法拼接起来.
如果这时再想分配一个比较大的块,就需要将这些不连续的外碎片“拼起来”,形成一个大的连续块。然而这是一件开销很大的事情,涉及到极大的内存读写开销。具体而言,这需要移动和调整一些已分配内存块在物理内存上的位置,才能让那些小的外碎片能够合在一起,形成一个大的空闲块。如果连续内存分配算法选取得当,可以尽可能减少这种操作。操作系统课上所讲到的那些算法,包括 first-fit/worst-fit/best-fit 或是 buddy system,其具体表现取决于实际的应用需求,各有优劣。
分页内存管理
看完这一节之后,我想到的内容就是有关于 视角不同 的思考,可以看到段内存分配的时候,我们总是 惯着 APP,总是希望我们的内存分配系统去 配合 APP的一些内存特性.
但是看了这一节之后,我们可以理解到,实际上对APP的内存进行分割管理也许是一种未曾想过的道路.
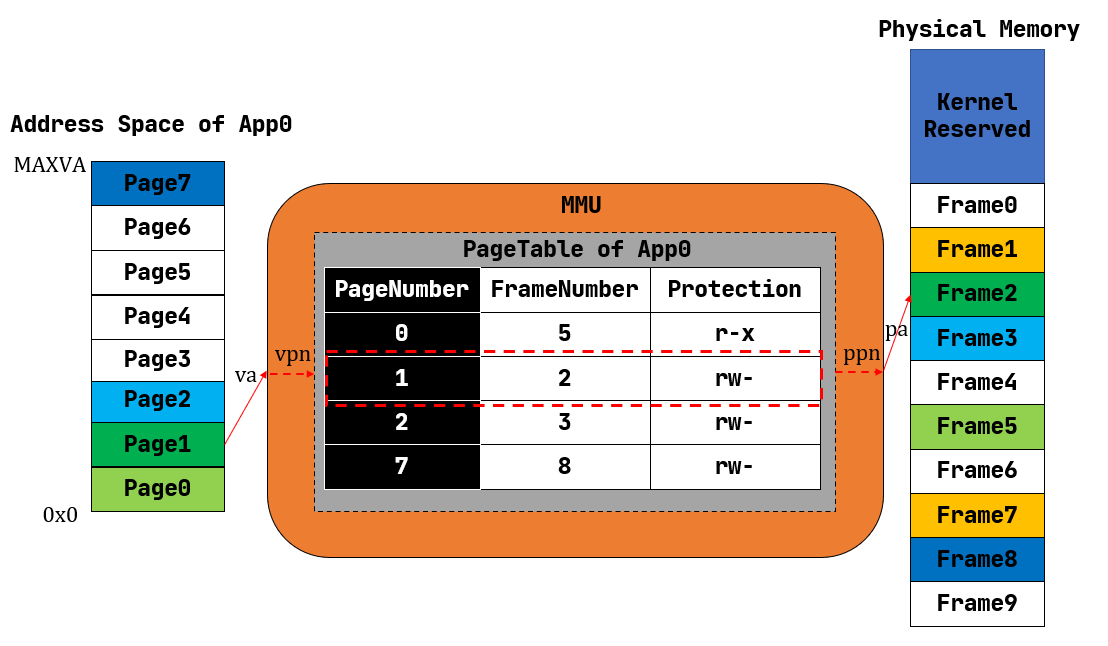
同样是进行看图说话.
可以看到,对每个应用的 地址空间 进行了 分页 .
那么每个地址空间的 虚拟页号 都可以通过MMU转换为一个 物理页号 .
这样的化其实相当于还是用了 分配一个固定大小的内存 的方法,只不过 粒度更小 .
每个应用都有一个表示地址映射关系的 页表 (Page Table) ,里面记录了该应用地址空间中的每个虚拟页面映射到物理内存中的哪个物理页帧,即数据实际被内核放在哪里。
我们可以用页号来代表二者,因此如果将页表看成一个键值对,其键的类型为虚拟页号,值的类型则为物理页号。当 MMU 进行地址转换的时候,虚拟地址会分为两部分(虚拟页号,页内偏移),MMU首先找到虚拟地址所在虚拟页面的页号,然后查当前应用的页表,根据虚拟页号找到物理页号;最后按照虚拟地址的页内偏移,给物理页号对应的物理页帧的起始地址加上一个偏移量,这就得到了实际访问的物理地址。
这里更加的准确了,不仅要对应到对应的 页号 ,那么对于一个准确的内存地址,也有一个 偏移值 .
那么图中还有一个
Protevtion
的段,很好理解是加入了读写的保护,但是我们知道所谓的保护其实是
写在OS里的逻辑
,那么具体是怎么实现( 通过
触发异常
)的也很重要:
在页表中,还针对虚拟页号设置了一组保护位,它限制了应用对转换得到的物理地址对应的内存的使用方式。最典型的如
rwx,r表示当前应用可以读该内存;w表示当前应用可以写该内存;x则表示当前应用可以从该内存取指令用来执行。一旦违反了这种限制则会触发异常,并被内核捕获到。通过适当的设置,可以检查一些应用在运行时的明显错误:比如应用修改只读的代码段,或者从数据段取指令来执行。
标签:游戏攻略







