你好呀,我是歪歪。
昨天分享了一下 《腾讯云 4 月 8 日故障复盘及情况说明》 ,较为详细的描述了故障前后的具体情况。
按照惯例,这种大公司的故障说明,歪师傅都是要好好看一下的。
一来是看看有没有可以学习的地方,多从别人的事故中总结经验教训,学习避坑指南。
二来还可以蹭个热点。
表扬
首先,先说说我个人认为值得表扬的地方。
第一点是文中把“云服务类比为酒店”这个比喻我觉得是真不错。
先是刨去所有的细枝末节,把云服务大概分为数据面和控制面,这两大坨。
然后用比较正式的语言描述了数据面和控制面分别是啥:数据面承载客户自身的业务,控制面负责操作云上不同产品。
接着用了一个实际的例子,比如 IaaS(Infrastructure as a Service),即基础设施服务,基本上都是以直接面向数据面为主,控制面仅在客户购买或需要对资源层面进行调整操作时会涉及。
此次发生故障的控制台和云 API 是对控制面的影响。
这段话是相对比较技术性的,如果让歪师傅用通俗的话来说就是:你买了腾讯云的服务器,马上就要到期了,但是你在服务器上部署了一个应用,还想继续用,所以你想着去续费。
腾讯云故障的时候,你服务器上的应用是没有问题的,但是如果你想续费,你得登录到腾讯云管理台,去充值。
由于故障期间管理台完全登录不了,所以对应的功能就用不了,因此这个时候是充值不了的。
除了续费外,控制台其实还能看很多的基础数据,服务运行情况等等,是一个信息收集门户,还是比较重要的。
但是上面这些话,不管是腾讯云的官方公告还是歪师傅举的续费的例子,对于非技术人员,理解起来可能都有一点点门槛。
然后腾讯云在公告里面举了一个例子:
通俗来讲,如果把云服务类比为酒店,控制台相当于酒店的前台,是一个统一的服务入口。一旦酒店前台发生故障,会导致入住、续住等管理能力不可用,但已入住的客房不受影响。
...
但是,用API提供的服务类产品(需要“酒店前台服务“)有不同程度的影响...
非常形象的比喻,一下就让那一部分可能一点都不懂技术的腾讯云客户找到了一个容易理解的抓手。
公告中这个比喻,我觉得很好。
第二个我认为值得表扬的点,就是这篇故障公告。
看得出来腾讯的这份事故报告写的还是有诚意的,较为详细的复盘了当时的情况。
我个人浅显的认为,其实它完全可以不用对公众发布这样一篇事故情况详细说明,可以只是对事故情况进行简单的描述,表达自己的歉意,然后做好客服培训,做好用户解释工作,启动相关赔偿流程就可以了。
详细说明,可以关起门来,仔细分析。
但是它发了,而且是在事情的热度已经算是过去了的情况下,发布的内容比较详细,一定程度上做的了对用户透明,在认错态度上,这一点是值得肯定的。
第三个点是我确实领到了 100 元无框门代金券的赔偿,也在不经意间带领一些小伙伴薅到了这 100 元的赔偿,相关情况在这篇文章里面说过了,就不多说了: 《腾讯云,你怎么回事?》
100 块钱确实不多,对于企业用户肯定是走另外一套赔偿流程,但是对于只是受到轻微影响的个人用户来说,总比没有好。
对于完全没有受到影响,纯薅了 100 元羊毛的用户来说,你就偷着乐就完事了。
我要说的表扬的点,大概就这三个了。毕竟是一次事故,也不能老是找表扬的角度,还是要找找可以改进的地方。
学习到的地方
表扬一般对应着批评。
但是歪师傅是个什么玩意,凭什么资格去批评腾讯云?
不够资格,所以我只是站在个人的角度,看看在这次事件中,我可以学习到的东西。
首先第一个还是“公告”,但是这个公告不是指前面提到的复盘公告,而是在事故当天,腾讯云官方微博发布的这些公告:
在言语中是有“抖机灵”的倾向的,说老实的,我第一眼看到这些描述的时候没有觉得任何问题,因为我已经得到了我想要的信息。
但是看网友讨论的时候,就相当一部分人在批评官方的“抖机灵”行为,看起来不是特别的正式,甚至有人说“读出了一丝吊儿郎当的感觉”。
如果一个公司、一个企业的老板,因为使用你们的产品,由于你们本次的故障,给公司、企业带来了麻烦,甚至是巨大的损失,当他们看到你不正式的言语的时候,内心并不会觉得幽默。
我想腾讯云微博的小编在对待整个事件,发布相关描述的时候一定也是非常认真的,只是用了一种自己觉得无伤大雅的方式。
但是借用一句网络名言:被误解是表达者的宿命。
话说出去,人们总是能找到各种解读的角度的。
所以在这种较为正式严肃的场景下,用官方的书面用语来进行事实的描述,虽然少了一份“活泼”,但是至少不会弄巧成拙。
这是我学习到的一个点。这一个点和“技术”毫无关系,但是站在更长远的视野中,比起技术,这个点的灵活运用可能更为重要。
写这篇文章的时候我本来想去看看对应微博下的评论的,但是发现已经被删除了,不知道背后有没有什么故事。
除了上面这个非技术的点外,当然也学到了一些技术方面的点。
整个故障复盘及情况说明,其实总结起来还是这九个字:
可监控!可灰度!可回滚!
比如文中出现的这些监控相关的图片:
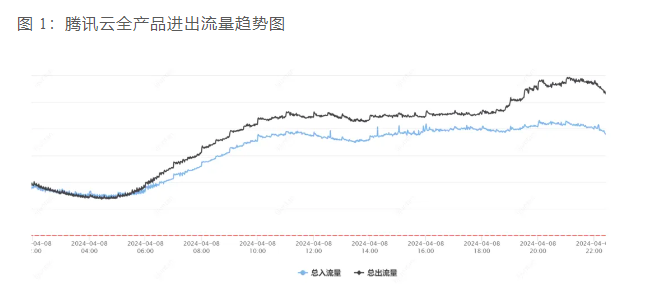
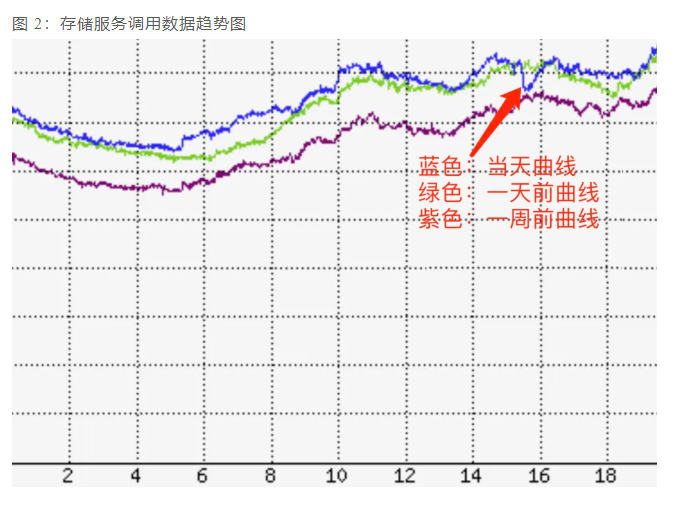
基于这些监控的图片,官方可以得出如下结论:
-
其他以非云 API 方式提供服务的 PaaS 和 SaaS 服务,处于正常服务的状态。 -
用 API 提供的服务类产品(需要“酒店前台服务“)有不同程度的影响,比如腾讯云存储服务调用当天有明显下滑。
关于“可灰度”,文章中有这样一句话,就直接提到了:
故障的原因是云 API 服务新版本向前兼容性考虑不够和配置数据灰度机制不足的问题。
在改进措施部分,也是直接提到了“实施灰度发布策略”:

这两个点结合起来,我理解就是有故障的这次发布没有按照灰度发布进行实施。
这一点确实是非常不应该的。
“可灰度”,在歪师傅公司是非常重要的一个指标,每次投产之前,有一个专门的检查项就是“是否可灰度”。
灰度期间可以用小波流量验证投产是否成功。如果没有灰度,直接流量全部放进来,程序又有问题,到时候哭都来不及。
如果不可灰度,需要写清楚不可灰度的原因,并且需要开专家评审会议,由专家再次讨论,确定是不是由于某些实际情况,本次应用的发布真的不可以灰度。
我也真的遇到过这样的“不可灰度”的发布,当时我是在关键逻辑处做了一个开关,在全面发布完成之前开关关闭,保持原逻辑。在全面发布之后,再把开关打开,先用内部流量来验证了本次投产是否成功。
结果真的有问题,本次投产失败,但是由于开关的存在,我立马把开关关闭了。
虽然投产失败了,但是没有引起大规模的问题,已经是不幸中的万幸了。
而这次投产,我拉着开发和测试同学前后一共分析了三次投产方案,投之前我还是非常自信的。
百密一疏,最后还是失败了。
但是投产失败带来的影响并不大,因为“可灰度”这三个字救了我,它让我反复去论证了投产方案,并进一步的考虑到了如果失败时的应对措施。
另外,再歪个楼。
关于“新版本向前兼容性考虑不够”描述中的“向前兼容性”,有一个朋友指出了描述不对:

实际情况也确实是“向后兼容不足”,这一点算是公告中的一个小错误吧。
至于“可回滚”,也是本次事件中的一个大漏洞。
因为回滚版本之后,服务并没有完全恢复,出现了意料之外的情况,说明实际情况并不满足“可回滚”:

公告中还有这样的描述:

“按照标准回滚方案”,我觉得其实就是选择上一个版本重新发布,因为这个动作放在任何一家公司,都是标准的回滚方案。
其实,除了标准的回滚方案之外,还应该有一个“本次投产的回滚方案”,方案中应该要包含本次服务回滚之后对于业务的影响和对于上下游服务的影响。以便真的出现问题的时候,作为后续执行方案决策的一个重要考虑部分。
比如,如果在投产之前,分析出了本次投产可能会影响到控制台,然后在分析“本次投产的回滚方案”时,理论上是能分析出可能会发生循环依赖的。
不要给我说你也不知道本次投产可能会影响到控制台,你做为一个开发人员,服务投产会影响到什么业务,应该是门清的,只是你可能没有时间去仔细分析。
如果分析出了“可能会发生循环依赖”,那么肯定就会进一步写解决方案:如果发生了循环依赖,导致服务无法自动拉起。需要通过运维手工启动方式使 API 服务重启。
这样,腾讯云就能减少 48 分钟的故障时间:
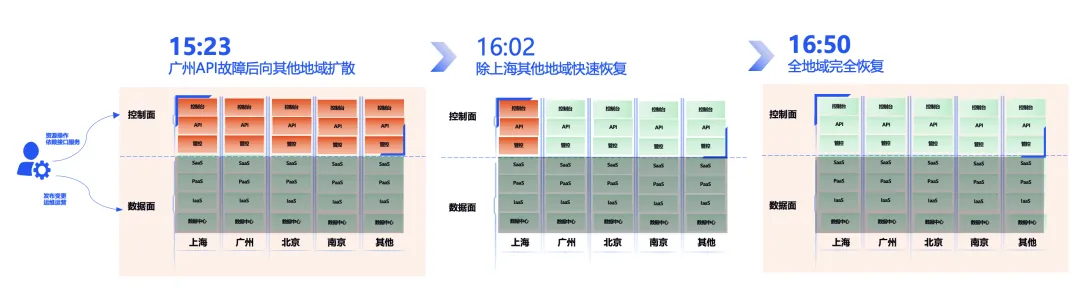
整体故障时间就是 39 分钟,还能保住 4 个 9 的高可靠性。
反正我是建议所有开发,运维,包括测试同学,都应该把“可监控,可灰度,可回滚”这九个字贴在工位上,刻在脑子里,做方案、写代码、提测前、上线前都把这九个字拿出来咂摸一下。
这九个字,说起来简单,但是落地是真的难。
虽然落地难,但是是真的可以保命的,至少保过我的命。
最后,还有一个点。
在重要的业务条线中、直接对客的核心业务中、基础能力服务中、关乎到公司名誉的业务中,等等相关业务中,涉及到调用外部接口,或者强依赖外部服务的地方,都应该要考虑到外部服务不可用的情况。
我知道这很难,就像是要你考虑 MySQL 彻底崩盘之后,你的服务应该怎么办一样的难。
但是怎么解决,能不能解决,花多大力气才能解决,这些问题都不重要,重要的是你要考虑到这个问题,并最好抛出问题,列出解决方案,让能决策的人进行决策,然后留痕,记录在案。
以防在真的出现问题的时候,遇到领导抛出这样的问题:当时为什么不考虑?不说?不给我说?
防止来自领导的致命追问是一方面,还有一个方面是其实大多数时候真的是有解决方案的。
还是拿腾讯云这次事件,举个最简单的例子。
我看公告中提到了这样一句话:

比如最后一个“验证码”,什么是验证码?
我在腾讯云查询了一下:

说白了,其实就是我们经常看到的这个玩意:
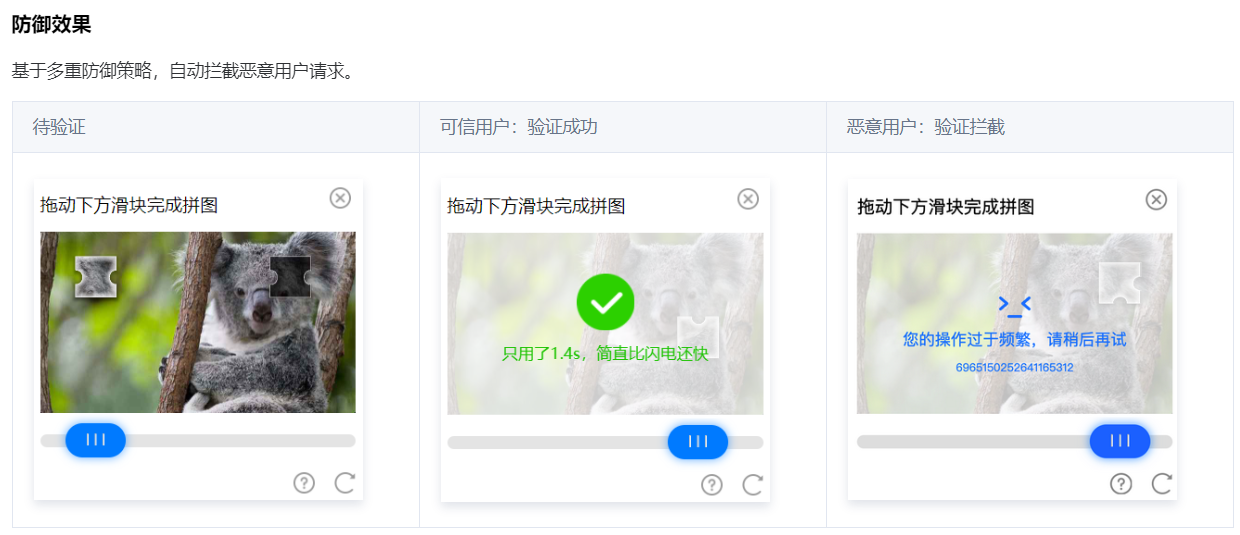
一般来说我们在用户登录注册的时候会用到,可以有效防止撞库攻击、阻止注册机批量注册小号。
现在你想象一个场景,你在登录某 APP 的时候要获取短信验证码,正常流程是在获取之前弹了个框,让你“拖动下方滑块完成拼图”。
结果这个“拼图”完成不了,你就获取不了验证码,从而导致你不能登录这个 APP。
正常来说,你就是骂一句:什么垃圾玩意。
然后就不登录了。
但是,如果这个 APP 是一个理财相关的 APP 呢?
站在用户角度:我靠,我本来是要来取点钱出来的,怎么登录不了了?不会是捐款跑路了吧?
你说用户慌不慌,他根本不知道是因为腾讯云故障导致的,他只是慌。
一慌就要打客服电话核实情况,结果客服功能也使用的是腾讯云,假设也受到了影响。
用户发现客服电话也打不通,心里一紧:卧槽,真跑路了?
你说巧不巧,这个人刚好在一个群里面,这个群里面全是买了这个理财产品的用户,平时在群里吹水聊天,交流韭菜心得。
于是他在群里喊一了声:理财 APP 你们赶紧看看是不是登录不上了,取不了钱了,是不是跑路了啊?
这样的舆情一旦开始发酵,轻则上面请公司负责人去喝茶,重则发生大规模挤兑事件,公司不一定扛得住。
而这一切,都是因为你核心业务的核心链路上依赖的核心服务出故障了。
怎么办?
很简单嘛,要么降级,根据实际业务场景,直接先跳过这个步骤,比如在这个火烧眉毛的时候了,获取验证码就别弹窗了,直接放开就完事。
或者备份嘛,多对接几个渠道,国内这么多云,再对接几个云的验证码服务,搞个热备、冷备、负载均衡啥的,这种按照调用量收费的,应急场景下也花不了几个钱。
我使用的图床工具叫做 PicGo,就连这小小的图床工具都提供了这么多接入方式:

你的核心业务还不值得花点钱多做点冗余吗?
再说了,退一万步说:
花的也不是你的钱。出了事儿,扣的可是你的钱。
你自己好好咂摸咂摸。
标签:游戏攻略







