大家好,我是 Weekoder!
今天要讲的内容是 矩阵加速!
这时候就有人说了:
\(\tiny{\texttt{Weekoder 这么蒻,怎么会矩阵啊。还给我们讲,真是十恶不赦!}}\)
不不不,容我解释。在经过我的研究后,我发现基本的矩阵运算和矩阵加速都并没有那么难。只要继续往下看,相信你也能学会!
注意:以下内容的学习难度将会用颜色表示,与洛谷题目难度顺序一致,即 \(\color{#FE4C61}\texttt{红}\color{#000000}<\color{#F39C11}\texttt{橙}\color{#000000}<\color{#FFC116}\texttt{黄}\color{#000000}<\color{#52C41A}\texttt{绿}\color{#000000}\) 。(并不对标洛谷题目难度,只作为学习难易度参考)
矩阵和二维数组很像,是由 \(m\times n\) 个数排列成 \(m\) 行 \(n\) 列的一张表,由于排列出来的表是一个矩形,故称其为矩阵。矩阵长这个样子:
可以看到,矩阵中的每个元素都有着对应的行和列,我们把一个矩阵记作 \(A\) ,第 \(i\) 行 \(j\) 列的元素即为 \(a_{ij}\) 。更形式化的,写作:
其中 \(\mathbb{F}\) 为 数域 ,一般取为实数域 \(\mathbb{R}\) 或复数域 \(\mathbb{C}\) 。(看不懂没事,蒟蒻自行走开QWQ)
\(\texttt{1.零矩阵}\)
元素全部为 \(0\) 的矩阵称为 零矩阵 。像这样:
零矩阵记作 \(0_{m\times n}\) ,就是在 \(0\) 下面加上矩阵的大小 \(m\times n\) 。你可以把零矩阵看做数字 \(0\) ,任何数乘以 \(0\) 都得 \(0\) 。
\(\texttt{2.对角矩阵}\)
只有主对角线上的元素有值,其余元素为 \(0\) 的矩阵称为 对角矩阵 。
注:主对角线为矩阵中 从左上角到右下角 的一条对角线。
对角矩阵根据主对角线上的值,记作 \(\text{diag(}\text{a}_1,\text{a}_2,\ldots,\text{a}_n\text{)}\) 。
\(\texttt{3.单位矩阵}\)
主对角线上的元素均为 \(1\) ,其余元素为 \(0\) 的矩阵称为 单位矩阵 。
单位矩阵记作 \(I\) 。
记得分数中的概念 分数单位 吗?矩阵单位和分数单位的“地位”差不多,代表的都是最 基础 的,最小的 独立个体 。你可以把单位矩阵看做数字 \(1\) ,任何数乘以 \(1\) 都等于它本身。
最基础的,常见的特殊矩阵就是这些了。当然,还有很多的特殊矩阵,不过我们暂时用不到。
\(\texttt{1.相等}\)
若对于矩阵 \(A,B\) ,所有的 \(i,j\) 都有 \(a_{ij}=b_{ij}\) 且矩阵的行和列相等,则称矩阵 \(A,B\) 相等。
其实就是两个矩阵长得 一模一样 。
\(\texttt{2.矩阵加(减)法}\)
若要求 \(A,B\) 两个矩阵之和,即 \(C=A+B\) ,则对于任意 \(i,j\) ,满足 \(c_{ij}=a_{ij}+b_{ij}\) 。要求矩阵行列相等。
总结一句话:对应位置相加。
矩阵加法满足交换律和结合律:
减法同理,对应位置相减。
\(\texttt{3.矩阵数乘}\)
数 \(\lambda\) (一个数字) 乘以矩阵 \(A\) ,记作 \(\lambda A\) ,即为矩阵数乘运算。若有 \(B=\lambda A\) ,则对于任意 \(i,j\) 都满足 \(b_{ij}=\lambda a_{ij}\) 。
还是一句话:对应位置相乘。
虽然矩阵乘法也属于矩阵运算,但难度比前面的都高,而且是今天的 重点内容 ,所以单独放出来讲,故记为 \(\texttt{Part 3.5}\) 。(话说你们没有发现难度变成黄了吗)
上 例题 !(虽然难度是橙)
先看矩阵乘法的定义:若有 \(n\) 行 \(m\) 列矩阵 \(A\) 和 \(m\) 行 \(k\) 列的矩阵 \(B\) ( \(A\) 的行与 \(B\) 的列相等),则 \(n\) 行 \(k\) 列的矩阵 \(C=A\times B\) 满足
只要枚举 \(i,j\) (范围是 \(n,k\) ),并套用公式就能用 \(O(n^3)\) 的时间复杂度解决这个问题。
我知道,这看起来根本不是新手蒟蒻能看懂的。那我就用人话来讲讲矩阵乘法。
矩阵乘法并不是一个一个乘,而是 行对应列乘 。怎么个乘法呢?我们来看看下面两个矩阵相乘的例子。
第一个矩阵为 \(A\) ,第二个矩阵为 \(B\) 。
我们先取出 \(A\) 的 第一行 。像这样:
再取出 \(B\) 的 第一列 。像这样:
不对,你给我转过来。
现在终于可以相乘了。逐位相乘得出结果:
得出了结果 \(\begin{pmatrix} 10 & 0 & 6 \end{pmatrix}\) 。再将每一位相加:
还记得我们之前是怎么取的吗?我们取了 \(A\) 的 第一行 和 \(B\) 的 第一列 (注意加粗部分),所以答案就存储在 \(C\) 的 第一行第一列 。还没搞懂?更通用一点:我们取了 \(A\) 的 第 \(x\) 行 和 \(B\) 的 第 \(y\) 列 (注意加粗部分),所以答案就存储在 \(C\) 的 第 \(x\) 行第 \(y\) 列 。也就是说,当我们想要获取矩阵 \(C\) 的第 \(x\) 行 \(y\) 列的时候,就需要取 \(A\) 的第 \(x\) 行和 \(B\) 的第 \(y\) 列,相乘再相加。由于 \(A\) 的行数与 \(B\) 的列数相等,取出来的数列才可以逐位相乘(不然元素个数不一样)。而取出来的数列长度就是 \(m\) ,所以可以用 \(O(m)\) 求和,总时间复杂度 \(O(nmk)=O(n^3)\) 。
最后,可以看看代码辅助理解。
#include <bits/stdc++.h>
using namespace std;
const int N = 105;
int n, m, k, a[N][N], b[N][N]; // 用二维数组存矩阵 A,B
int main() {
cin >> n >> m >> k;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> a[i][j]; // 输入矩阵 A
for (int i = 1; i <= m; i++)
for (int j = 1; j <= k; j++)
cin >> b[i][j]; // 输入矩阵 B
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= k; j++) { // 枚举 C 矩阵 n 行 k 列的每个元素
// 以下部分为模拟刚刚讲的矩阵乘法
int sum = 0; // 求和,sum 即为 C_ij
for (int l = 1; l <= m; l++)
sum += a[i][l] * b[l][j]; // 求和,A 的行和 B 的列,建议模拟一下过程加强理解
cout << sum << " "; // 输出 sum(C_ij)
}
cout << "\n"; // 记得换行!
}
return 0; // 完美的结束
}
这样就能愉快地切掉这道题了。请完成这道题再继续!
矩阵乘法满足以下性质:
结合律: \((AB)C=A(BC)\)
分配律: \((A+B)C=AC+BC\)
矩阵乘法 不满足 交换律。(这是重点!)
有了矩阵乘法,我们还可以结合上面的特殊矩阵得到一些性质:
快到今天的主题了!上 例题 !
点开题目后的你 be like:

这是啥呀?
我来让题目描述“缩点水”:
给定一个 \(n\) 行 \(n\) 列的矩阵 \(A\) ,求 \(A^k\) ,即 \(\underbrace{A\times A\times A\times\cdots\times A\times A}_{k\texttt{ 次}}\) 。
第一思路:暴力!直接做 \(k\) 次矩阵乘法,时间复杂度 \(O(kn^3)\) 。看看数据范围:
\(0\le k\le10^{12}\)
考虑放弃做题。
那我们该怎么优化呢?看到需要计算
\(A^k\)
,我突然想到了一个算法:快速幂!但是矩阵快速幂该怎么写呢?答案是:和正常的快速幂一样,矩阵也能使用快速幂,只不过快速幂中的乘法变成了矩阵乘法。但是矩阵乘法太难写,有没有什么办法能让矩阵乘法也像普通的乘法一样,只要写一个
*
乘号就行了呢?
注意:不会快速幂的话可以先简单看看 我写的文章 。
回到主题,有没有什么办法能只要写一个
*
乘号就能进行矩阵乘法呢?其实我们可以用结构体把矩阵封装起来,再用
重载运算符
就行了。关于重载运算符,可以参考
这些资料
。
定义一个矩阵类型的结构体可以写成这样:
struct Matrix {
};
我们需要在里面用一个二维数组存储矩阵。我们还可以写一个结构体初始化函数,只要定义了一个矩阵,就自动清零,免去清零的麻烦。
struct Matrix {
int a[N][N]; // N 为矩阵大小
Matrix() {
memset(a, 0, sizeof a);
}
};
最后,把矩阵乘法写进去。
struct Matrix {
ll a[N][N];
Matrix() {
memset(a, 0, sizeof a);
}
Matrix operator*(const Matrix &x)const {
Matrix res;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
for (int k = 1; k <= n; k++)
res.a[i][j] = (res.a[i][j] % MOD + a[i][k] % MOD * x.a[k][j] % MOD) % MOD;
return res;
}
};
注意,这里一定要写成
a[i][k] * x.a[k][j]
,不能写成
x.a[i][k] * a[k][j]
,因为矩阵乘法不满足交换律!
这样,结构体封装部分就完成了。
我们要定义两个矩阵: \(a\) 和 \(base\) 。 \(a\) 是输入的矩阵, \(base\) 是答案矩阵,所以 \(base\) 需要初始化成 \(I\) (单位矩阵),写一个初始化函数 \(\operatorname{init}\) ,如下:
void init() {
for (int i = 1; i <= n; i++) base.a[i][i] =1;
}
初始化完以后,就可以执行快速幂了,计算 \(A^k\) 了,让 \(base\) 乘 \(A\) 。矩阵快速幂核心代码如下:
void expow(ll b) {
while (b) {
if (b & 1) base = base * a;
a = a * a, b >>= 1;
}
}
有一点需要注意的就是,不能写成
base *= a
等形式,因为重载运算符定义的是
*
,没有定义
*=
,所以需要将
*=
展开。
最后,就可以输出 \(base\) 了。展示全部代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 105, MOD = 1e9 + 7;
int n;
ll k;
struct Matrix {
ll a[N][N];
Matrix() {
memset(a, 0, sizeof a);
}
Matrix operator*(const Matrix &x)const {
Matrix res;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
for (int k = 1; k <= n; k++)
res.a[i][j] = (res.a[i][j] % MOD + a[i][k] % MOD * x.a[k][j] % MOD) % MOD;
return res;
}
}a, base;
void init() {
for (int i = 1; i <= n; i++) base.a[i][i] =1;
}
void expow(ll b) {
while (b) {
if (b & 1) base = base * a;
a = a * a, b >>= 1;
}
}
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
cin >> a.a[i][j];
init();
expow(k);
for (int i = 1; i <= n; putchar('\n'), i++)
for (int j = 1; j <= n; j++)
cout << base.a[i][j] << " ";
return 0;
}
终于到了最后的 \(\color{red}\texttt{BOSS 关卡}\) 了!你们有信心吗?加油!
点击 此处 进入 \(\color{red}\texttt{BOSS 关卡}\) ......
点开
题目
\(\color{red}\texttt{BOSS 关卡}\)
后的你 be like(梅开二度):
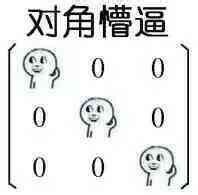
这和矩阵有什么关系吗???
我直接一个递推!
- 对于 \(100\%\) 的数据 \(1 \leq T \leq 100\) , \(1 \leq n \leq 2 \times 10^9\) 。
\(O(Tn)\) 这 \(2\times10^{11}\) 的复杂度实在无法接受。
(呜呜呜我再也不学 c艹 了)
没关系,先看看思路!
因为发现当 \(x\le3\) 时答案为 \(1\) ,所以这是最基础的情况。我们可以构造一个只有一列的矩阵:
显然,这三个元素都是 \(1\) 。
那么,假设我想要得到 \(a_4\) ,该怎么办呢?所以,我们需要进行一种运算,让上面的矩阵变化一下,像这样:
更加通用一点:
可以发现,矩阵中的每个元素的项数都向前推进了 \(1\) 。那么,我们大概可以写出伪代码:
如果 \(x\le3\)
输出 \(1\)
否则
执行运算 \(n-3\) 次(重要!)
并输出答案矩阵 \(1\) 行 \(1\) 列
特判(对于特殊情况的判断)和输出应该没什么问题,主要是为什么运算恰好要执行 \(n-3\) 次呢?稍微画个图模拟一下就好了。
还是假设要获取 \(a_4\) ,则执行运算 \(4-3=1\) 次。在执行 \(1\) 次运算后,
变为
这样就刚好在第 \(1\) 行 \(1\) 列得到 \(a_4\) 啦!
那么,说了这么久,这个神秘的运算是什么呢?当当当当~,他就是我们的——矩阵乘法!
没错,所谓的变换,其实就是乘上了一个特殊的矩阵!那么,这个矩阵长什么样呢?让我们一起来推理吧。
(此处应配上推理の小曲)
我们可以先列一个表格,表格的行代表矩阵 \(\begin{pmatrix}a_3 & a_2 & a_1 \end{pmatrix}\) 的元素,列代表递推时与这些元素相关的元素。像这样:(表格可能在博客里渲染不出来,凑合着看吧,抱歉)
| \(a_x\) | \(a_{x-1}\) | \(a_{x-2}\) | |
|---|---|---|---|
| \(a_{x-1}\) | |||
| \(a_{x-2}\) | |||
| \(a_{x-3}\) |
好了,对于 \(a_x\) ,我们该怎么填他那一列呢?我们可以观察到递推式 \(a_x=a_{x-1}+a_{x-3}\) ,所以有:
观察系数 \(1,0,1\) ,把这些系数填入表格中:
| \(a_x\) | \(a_{x-1}\) | \(a_{x-2}\) | |
|---|---|---|---|
| \(a_{x-1}\) | \(1\) | ||
| \(a_{x-2}\) | \(0\) | ||
| \(a_{x-3}\) | \(1\) |
后面的也以此类推:
| \(a_x\) | \(a_{x-1}\) | \(a_{x-2}\) | |
|---|---|---|---|
| \(a_{x-1}\) | \(1\) | \(1\) | \(0\) |
| \(a_{x-2}\) | \(0\) | \(0\) | \(1\) |
| \(a_{x-3}\) | \(1\) | \(0\) | \(0\) |
这样,我们就可以推出这个神秘的矩阵了:
好了,现在我们终于知道了,一次神秘操作,就是将让 \(\begin{pmatrix}a_3 & a_2 & a_1 \end{pmatrix}\) 这个矩阵乘上 \( \begin{pmatrix} 1 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{pmatrix} \) 。这时候就有人问了:
一次矩阵乘法的时间复杂度还没有递推快,这根本就没有优化嘛。
等等!我们把这个式子展开:
不是吧!这居然变成了一个矩阵快速幂?!!
也就是说,我们可以用快速幂计算 \(\begin{pmatrix} 1 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{pmatrix} ^{n-3}\) ,并乘上初始矩阵 \(\begin{pmatrix} 1 & 1 & 1 \end{pmatrix}\) 。这样,我们成功地把时间复杂度从 \(O(Tn)\) 优化到了 \(O(T\log n)\) !(矩阵快速幂是 \(O(\log n)\) ,因为矩阵很小,矩阵乘法只计算 \(9\) 次,是一个很小的常数)
下面奉上代码:(标准的矩阵加速思想)
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int MOD = 1e9 + 7;
int T, n;
struct Matrix {
ll a[5][5];
Matrix() {
memset(a, 0, sizeof a);
}
Matrix operator*(const Matrix &x)const { // 矩阵乘法
Matrix res;
for (int i = 1; i <= 3; i++)
for (int j = 1; j <= 3; j++)
for (int k = 1; k <= 3; k++)
res.a[i][j] = (res.a[i][j] % MOD + a[i][k] % MOD * x.a[k][j] % MOD) % MOD;
return res;
}
void mems() {
memset(a, 0, sizeof a);
}
}ans, base;
void init() { // 初始化两个矩阵
ans.mems(), base.mems(); // 记得清空!
ans.a[1][1] = ans.a[1][2] = ans.a[1][3] = 1;
base.a[1][1] = base.a[1][2] = base.a[2][3] = base.a[3][1] = 1;
}
void expow(int b) { // 矩阵快速幂,是在 ans 矩阵的基础上乘的
while (b) {
if (b & 1) ans = ans * base;
base = base * base, b >>= 1;
}
}
int main() {
cin >> T;
while (T --) {
cin >> n;
init(); // 初始化不能忘
if (n <= 3) { // 特判
cout << "1\n";
continue;
}
expow(n - 3); // 计算特殊矩阵的 n - 3 次方,已经乘到了 ans 里
cout << ans.a[1][1] << "\n"; // 输出答案!芜湖!
}
return 0; // 快乐结束
}
就这样,我们完成了矩阵加速递推。
再次声明矩阵快速幂(矩阵加速)时间复杂度: \(O(N^3\log n)\) ,其中 \(N\) 为矩阵的行数(列数), \(n\) 为快速幂的规模 \(a^n\) 。
小提示:关于 \(base\) 矩阵的构造
就是这个 \(\begin{pmatrix} 1 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{pmatrix}\) 矩阵。
可以这样:我们要推导出 \(\begin{pmatrix}a_x & a_{x-1} & a_{x-2}\end{pmatrix}\) ,那么这个矩阵从哪里来?当然是从 \(\begin{pmatrix}a_{x-1} & a_{x-2} & a_{x-3}\end{pmatrix}\) 来。所以,表格才长这样:
| \(a_x\) | \(a_{x-1}\) | \(a_{x-2}\) | |
|---|---|---|---|
| \(a_{x-1}\) | |||
| \(a_{x-2}\) | |||
| \(a_{x-3}\) |
那么,能不能构造一个行列数各不相同的矩阵,而不是一个 \(n\times n\) 的矩阵呢?答案是不可以,因为我们要计算 \(\begin{pmatrix} 1 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{pmatrix}\) 这种矩阵的幂,那如果行和列不相等,相乘的两个矩阵的行列也不相等,就无法进行矩阵乘法。比如这个:
可以看到,左边 \(2\) 行,右边 \(3\) 列,显然不相等,无法进行矩阵乘法。
这篇文章花费了我很多时间,希望你喜欢!
对了,你学会了吗?是不是,矩阵也并没有那么难?
这应该是我的【精选】文章中的第一篇,没想到写的是矩阵方面的。
总之,很感谢你的阅读!希望你能从我这学到点东西!
再见!
标签:游戏攻略







