
前一篇:《用于自然语言处理的循环神经网络RNN》
序言: 本节主要讲解如何使用循环神经网络(RNN)创建一个文本分类器。RNN 是一类适合处理序列数据的神经网络的统称,而我们将在本节中使用 RNN 的一种常见变体——LSTM(长短期记忆网络)来实现这一文本分类器。
使用RNN创建文本分类器
在第六章中,你尝试使用嵌入层为讽刺数据集创建分类器。在那种情况下,单词会先被转换为向量,然后聚合后再输入全连接层进行分类。而如果使用RNN层(例如LSTM),则不需要聚合,可以直接将嵌入层的输出传递到循环层中。
关于循环层的维度,有一个常见的经验法则是:它的大小通常和嵌入维度相同。这并不是必须的,但可以作为一个不错的起点。注意,在第六章中我提到嵌入维度通常是词汇量的四次方根,但在使用RNN时,这个规则往往会被忽略,因为如果遵循这个规则,循环层的维度可能会太小。
例如,第六章中开发的讽刺分类器的简单模型架构,可以更新为如下形式,以使用双向LSTM:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
损失函数和分类器可以设置为以下内容(注意学习率为0.00001或1e–5):
adam = tf.keras.optimizers.Adam(learning_rate=0.00001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics=['accuracy'])
当打印出模型架构的摘要时,你会看到类似以下的内容。注意,词汇量大小为20,000,嵌入维度为64。这会在嵌入层中产生1,280,000个参数,而双向层会有128个神经元(64个前向,64个后向):
Layer (type) Output Shape Param #
=================================================================
embedding_11 (Embedding) (None, None, 64) 1280000
bidirectional_7 (Bidirection) (None, 128) 66048
dense_18 (Dense) (None, 24) 3096
dense_19 (Dense) (None, 1) 25
=================================================================
Total params: 1,349,169
Trainable params: 1,349,169
Non-trainable params: 0
图7-9显示了经过30个epoch的训练结果。
正如你所见,网络在训练数据上的准确率迅速超过90%,但在验证数据上稳定在80%左右。这与我们之前得到的结果类似,但检查图7-10中的损失图表可以发现,尽管验证集的损失在15个epoch之后有所分歧,但它趋于平稳,且相比第六章中的损失图表,值更低,即使使用了20,000个单词,而不是2,000个。
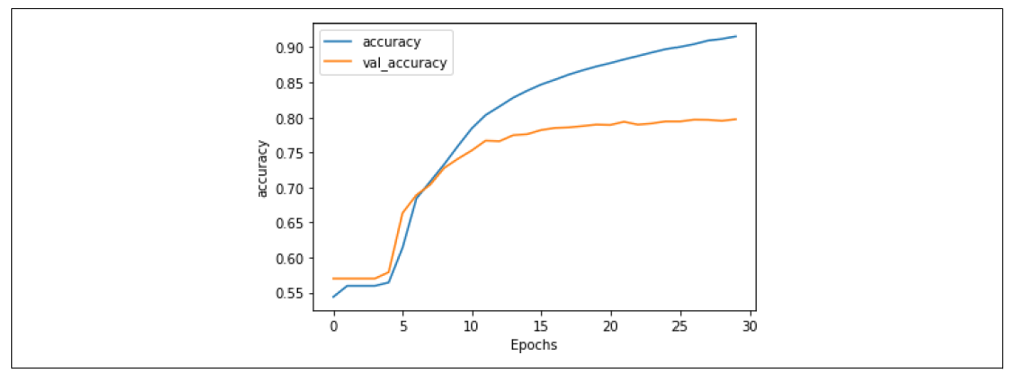
图7-9:LSTM在30个epoch中的准确率
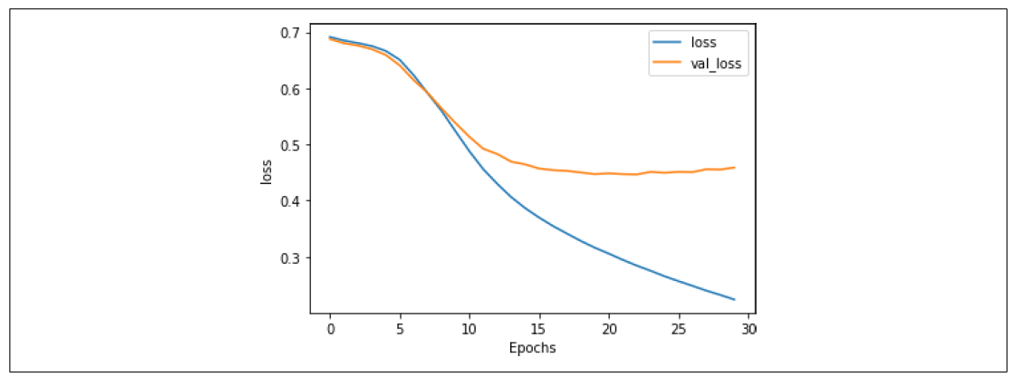
图7-10:LSTM在30个epoch中的损失
不过,这只是使用了单个LSTM层。在下一节中,你将看到如何使用堆叠的LSTM层,并探索其对该数据集分类准确率的影响。
堆叠 LSTM
在上一节中,你已经了解了如何在嵌入层后使用 LSTM 层来帮助对讽刺数据集进行分类。但实际上,LSTM 可以堆叠使用,这种方法在许多最先进的自然语言处理模型中被广泛采用。
在 TensorFlow 中堆叠 LSTM 非常简单。你可以像添加全连接层一样添加额外的 LSTM 层,但有一个例外:除最后一层外,所有层都需要将 return_sequences 属性设置为 True。以下是一个示例:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
最后一层也可以将 return_sequences=True 设置为 True,这样它会返回值序列供全连接层分类,而不是单个值。在解析模型输出时,这种设置可能非常有用,我们稍后会讨论这一点。
模型架构将会如下所示:
Layer (type) Output Shape Param #
=================================================================
embedding_12 (Embedding) (None, None, 64) 1280000
bidirectional_8 (Bidirection) (None, None, 128) 66048
bidirectional_9 (Bidirection) (None, 128) 98816
dense_20 (Dense) (None, 24) 3096
dense_21 (Dense) (None, 1) 25
=================================================================
Total params: 1,447,985
Trainable params: 1,447,985
Non-trainable params: 0
添加额外的 LSTM 层将增加大约 100,000 个需要学习的参数,总量增加了约 8%。虽然可能会稍微减慢网络速度,但如果带来了合理的性能提升,这个代价还是可以接受的。
经过 30 个 epoch 的训练后,结果如图 7-11 所示。虽然验证集的准确率表现平稳,但查看损失(图 7-12)会揭示一个不同的故事。
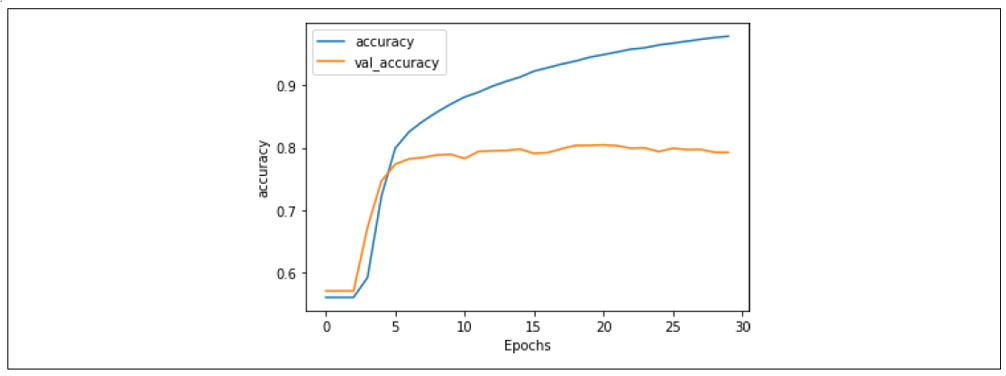
图 7-11:堆叠 LSTM 架构的准确率
从图 7-12 可以看出,尽管训练和验证的准确率表现良好,但验证集的损失迅速上升,这是过拟合的明显迹象。
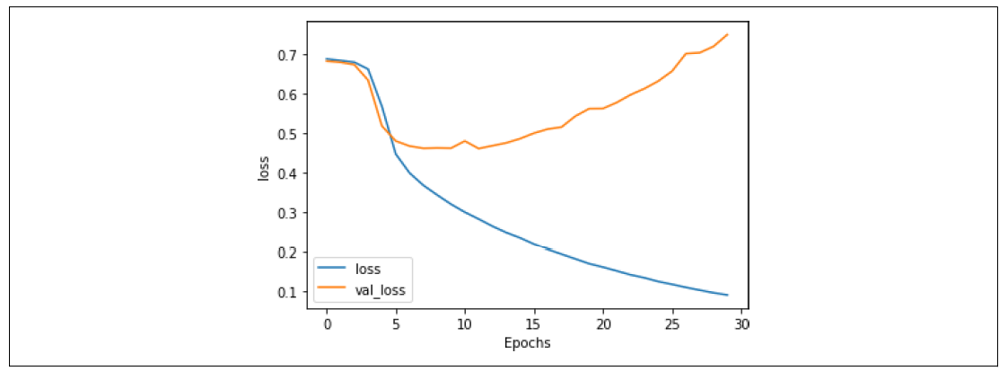
图 7-12:堆叠 LSTM 架构的损失
这种过拟合的表现为:训练准确率逐渐接近 100%,损失平稳下降,而验证准确率相对稳定,但验证损失急剧上升。这说明模型对训练集过于专注而产生了过拟合问题。正如第六章的例子所示,仅查看准确率指标可能会让人产生一种错误的安全感,因此必须结合损失图表分析。
优化堆叠 LSTM
在第六章中,你已经看到一个非常有效的减少过拟合的方法是降低学习率。可以探索一下这个方法对循环神经网络是否也有积极影响。
例如,以下代码将学习率从 0.00001 降低了 20%,变为 0.000008:
adam = tf.keras.optimizers.Adam(learning_rate=0.000008, beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
图 7-13 展示了这种变化对训练的影响。虽然差异不大,但曲线(尤其是验证集)变得更加平滑了。
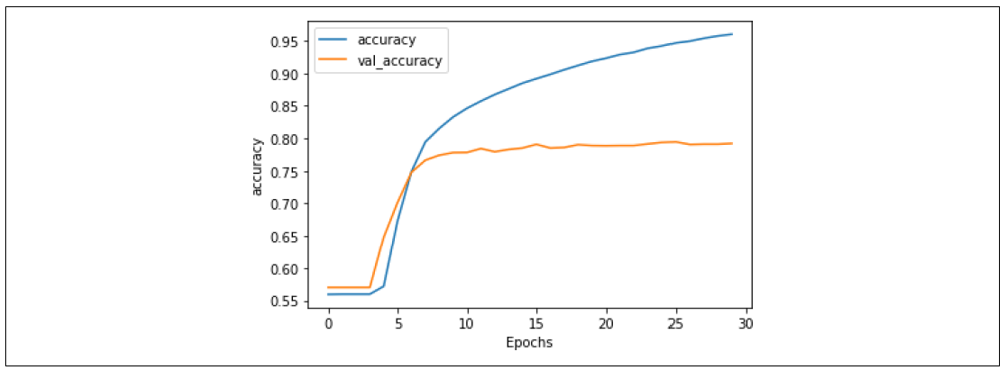
图 7-13:降低学习率对堆叠 LSTM 准确率的影响
类似地,查看图 7-14 也显示,虽然整体趋势类似,但降低学习率使得损失增长速度明显降低:在 30 个 epoch 后,损失约为 0.6,而更高学习率时接近 0.8。这表明调整学习率超参数是值得探索的。
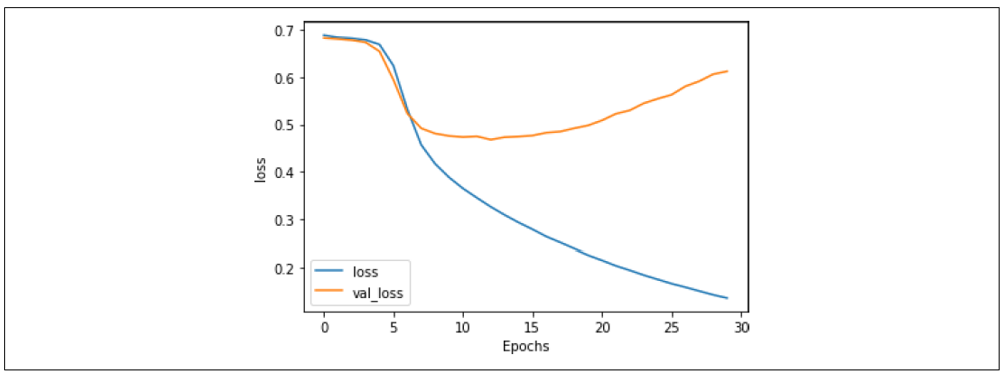
图 7-14:降低学习率对堆叠 LSTM 损失的影响
使用 Dropout
除了调整学习率,还可以考虑在 LSTM 层中使用 Dropout。正如第三章所讨论的,Dropout 的作用是随机丢弃一些神经元,以避免由于邻近神经元的影响而产生的偏差。
在 LSTM 层中,可以通过一个参数直接实现 Dropout。例如:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True, dropout=0.2)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, dropout=0.2)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
需要注意的是,使用 Dropout 会显著降低训练速度。在我的实验中,在 Colab 上训练时间从每个 epoch 大约 10 秒增加到了 180 秒。
使用 Dropout 的准确率结果见图 7-15。从图中可以看到,Dropout 对网络的准确率几乎没有负面影响,这是一件好事!通常人们会担心丢弃神经元会让模型表现更差,但这里显然不是这样。
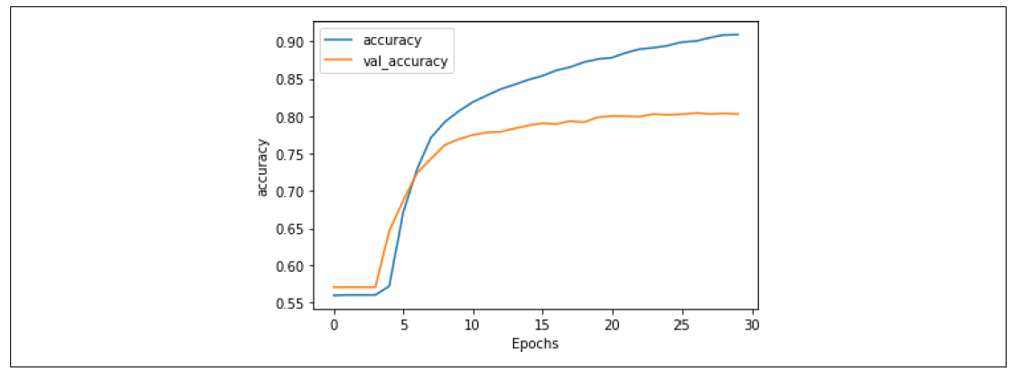
图 7-15:使用 Dropout 的堆叠 LSTM 的准确率
此外,对损失也有积极影响,如图 7-16 所示。尽管曲线明显分离,但相比之前,它们更接近了,并且验证集的损失趋于平稳,约为 0.5,比之前的 0.8 要好得多。这个例子表明,Dropout 是一种能够改善基于 LSTM 的 RNN 性能的实用技术。
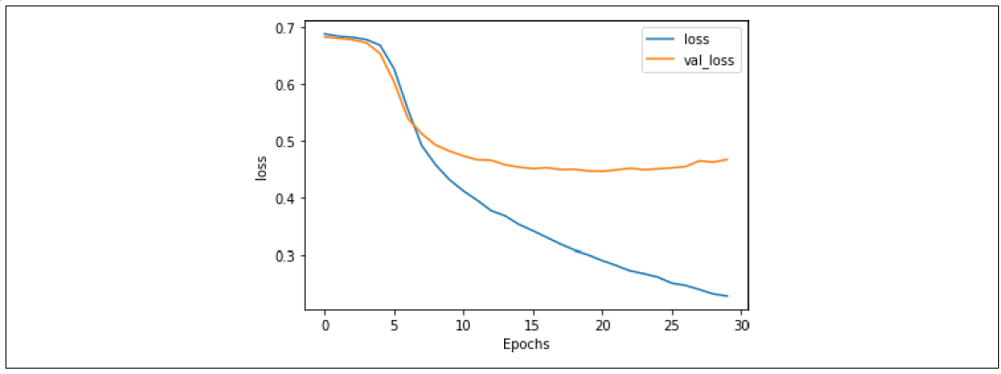
图 7-16:启用 Dropout 的 LSTM 损失曲线
探索这些技术来避免数据过拟合是值得的,同时也要结合前几节中介绍的数据预处理技术。但还有一种方法我们尚未尝试——一种使用预训练词嵌入替代自学嵌入的迁移学习方法。我们将在下一节中探索这一内容。
总结: 本篇文章详细讲解了如何利用 LSTM 神经网络构建高效的文本分类器,并通过优化学习率、堆叠层数及应用 Dropout 等方法,提升模型性能,避免过拟合,为文本处理任务提供了实用的实现方案。
标签:游戏攻略







